【IT168 现场报道】2013年4月18-20日,第四届中国数据库技术大会(DTCC 2013)在北京福朋喜来登酒店拉开序幕。在为期三天的会议中,大会将围绕大数据应用、数据架构、数据管理(数据治理)、传统数据库软件等技术领域展开深入探讨,并将邀请一批国内顶尖的技术专家来进行分享。本届大会将在保留数据库软件应用实践这一传统主题的基础上,向大数据、数据结构、数据治理与分析、商业智能等领域进行拓展,以满足于广大从业人士和行业用户的迫切需要。
自2010年以来,国内领先的IT专业网站IT168联合旗下ITPUB、ChinaUnix技术社区已经连续举办了三届数据库技术大会,每届大会超过千人规模,云集了国内技术水平最高的数据架构师、DBA、数据库开发工程师、研发总监、IT经理等,是目前国内最受欢迎的数据库技术盛会。

在DTCC2013大会数据管理专场,来自百度的资深工程师钱一峰为我们带来了《百度大规模存储系统》非常好的实践。钱一峰从百度目前数据的介绍、百度的存储系统、以及目前面临的挑战、百度目前新的存储体系和经验教训这些方面详细分享了百度大规模存储系统非常好的实践。

▲百度资深工程师钱一峰
钱一峰介绍到,百度目前的数据量已经达到了如下的规模:网页&超链达到10PB ~ 50PB,日志+数据仓库达到100PB + 10PB,广告达到1TB,UGC达到1PB,个人云也达到了5PB。
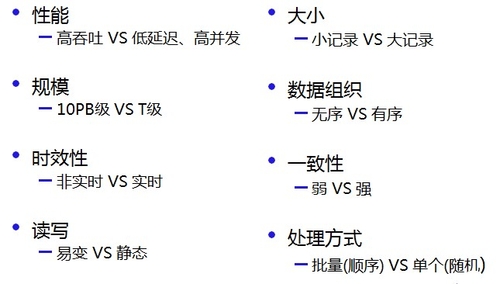
▲百度数据的特点
目前,百度的存储系统是通过Bailing(网页库)来实现海量和高吞吐,通过Mola(Key-Value存储)实现低延迟与高并发,通过Peta(HDFS2)来实现无序和大数据,通过DDBS(分布式数据库)来实现复杂关系和强一致。
钱一峰还介绍了目前百度所面临的挑战,他谈到,“首先是One Baidu One Storage,第二是海量与实时的挑战,三是高吞吐与低延迟、高并发,四是一致性,五是可扩展性,六是可用性与可靠性,七是如何利用新硬件(SSD,ARM,etc),最后是平台化(服务化)的问题。”
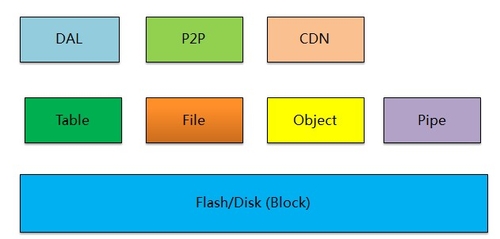
▲百度新存储体系
最后,钱一峰介绍了百度的经验教训,首先是项目一开始做的越简单越好,复杂容易出错;谁做的谁负责,考虑到未来运维的代价;能自动化的都要自动化;分层设计,把问题放在最适合的层次来解决;考虑到3~5年就好,而不用考虑到10年或更久的时间;平台化/服务化,提升开发效率,降低开发成本,节省运维和硬件的成本。

