【IT168 专稿】可以说Join的顺序是查询优化过程中最复杂的问题(当然,这里说的复杂,是对于查询优化器而言,我们很多时候没有看到,也没用怎么在意这个复杂性),因为它涉及到了为每个可选的Join的顺序计算成本。可以这样说:Join的顺序与个数直接与产生候选的执行计划的数量挂钩,从而极大的影响查询优化器的优化过程。
提到Join,我们都很熟悉了:就是把来自两个表的基于一些公共的信息进行联合的操作。Join的操作每次都只能在两个表之间进行,因此,如果一个查询要Join的表有N个,那么,就需要进行(N-1)次的Join操作,即:先第1个表和第2个表Join,然后Join的结果在和第3个表进行Join,以此类推。
关于Join,查询优化器会根据以下两点做出重要的决定:
1. Join顺序的选择
2. Join算法的选择
在这部分,我们重要谈谈Join的顺序的问题,相信看完之后,一定会让大家对Join有一个全新的认识,至于Join算法,因为这涉及到了执行引擎的部分,我们会在后面的文章中讲述。
之前提过,表的Join的顺序决定了一个查询的性能与成本。对已一个查询而言,可以产生很多的候选执行计划,虽然这些执行计划返回的结果一样,但是不同的Join产生的执行计划的成本确实相差很大的。
因为Join操作有着交换律和结合律的特性,所以,即使一个再简单的查询,也会因为Join的顺序不同而产生很多不同的执行计划,而执行计划的数量也会随着Join表的个数的增加而呈指数倍的增加。而查询优化器的任务就是在这些众多的执行计划中选择一个比较优的Join顺序的执行计划。
为了便于理解,我们先来看看几个概念,然后深入的讲述一些例子。
首先看看“交换律”。这一个数学概念,因为SQL Server是关系型数据,其理论基础就是关系集合论,而现在的数学都是建立在集合的基础上的,因此SQL Server在设计的时候,也引入了很多的数学的理论。Join操作的就体现了交换律:A Join B等于B Join A。
交换律也定义了哪一个表被先访问,例如在一个Nest Loops Join的操作中,首先被访问的表就被称之为“外部表”,而第二个表就称之为“内部表”。在Hash Join中,首先被访问的表称之为“内部构建表”,第二个表为“探针输入”。定义哪一个表为“外部表”或者为“内部构建表”、“探针输入”对性能的影响都是巨大的。
Join操作的另外一个特性就是:结合律,即:(A Join B) Join C等于A Join (B join C),这个概念也不难理解。下面,我们就通过一个实例来看看。
我们AdventureWorks示例数据库为例子,我们为下面的这个查询产生实际的执行计划:

我们来看看执行计划,如下:
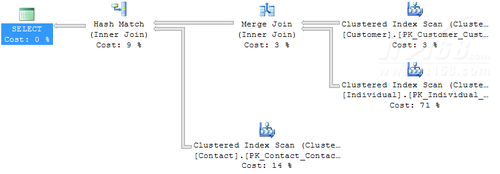
可以看出:
1. 我们在代码中Join的顺序是:(Contact Join Individual)Join Customer,但是在执行计划中的Join顺序却是:(Sales.Customer JOIN Sales.Individual) JOIN Person.Contact。
从这里就可以知道:我们在代码中的Join顺序,不见得就是最后执行计划的顺序,也证明了网络上面流行的一些偏方是错误的:通过改变Join的顺序来提升性能。因为查询优化器相当的智能,对于Join的顺序,它有着自己的决定和考虑。
2. 查询优化器会根据很多的信息来决定到底逻辑的Join操作最后又哪一种物理Join操作来执行。在例子的代码中,我们的Join都是逻辑的Inner Join,但是最后查询优化器会选择合适的物理Join操作,例如对于(Sales.Customer JOIN Sales.Individual),选择的就是Merge Join,因为这个两个表是基于聚集索引进行连接,并且数据都是按照聚集索引来排序的(更多的讲述,我们后面文章会涉及)。
${PageNumber}当然,我们也可以通过使用Hint来要求查询优化器按照我们的要求来强制的产生Join的类型和顺序,我们来看下面的一个例子:
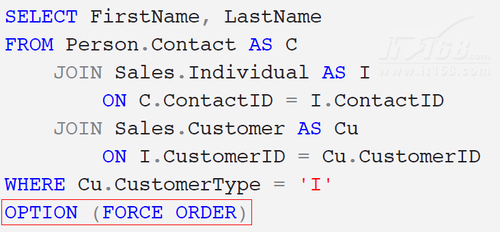
这时候,产生的执行计划如下:
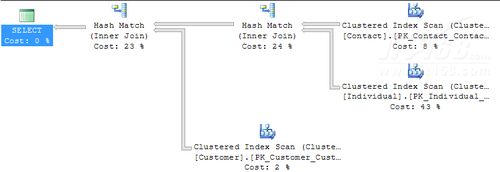
可以看出,查询优化器按照我们的要求进行了Join的连接顺序。
我们诚然可以通过使用Hint来改变查询优化器的行为,但是我们同时也要注意每个执行执行的成本。很多时候,我们使用Hint会带来很多的问题,而且查询优化器常常会选择比较好的执行方式和执行计划(在我们提供了正确的信息的情况下,例如统计信息等)。
我们之前提到过:表的Join的顺序会随着表数量的增长而呈指数倍的增加。而实际的情况是,只有很少的一些表,它们的Join的顺序的组合方式的数量会达到成千上万,组合的方式的数量主要取决于查询树的结构。而且,查询优化器也不可能为这个每一种组合都去进行成本估算,而是采用启发式的算法,根据查询树的结构和形状来减少搜索的空间。
这里可能不怎么好理解,我们稍微的讲一讲。
在之前的相关文章中介绍过:一个提交的查询语句经过一些处理之后,会以树状的结构出现在查询处理器中,而树形的结构对查询优化器来说又是至关重要的。树形的结构基本可以分为:左深度树,右深度树,多路树。
例如,对于:JOIN( JOIN( JOIN(A, B), C), D)这样的语句而言,可能产生左深度树或者右深度树,如图所示:
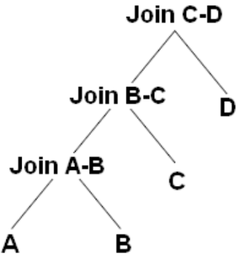
而对于:JOIN(JOIN(A, B), JOIN(C, D))的语句,可能产生下面的树:
根据表数量的不同,Join的顺序会产生很多的不同的树形,而这不同的树形最终会产生出不同的执行计划。
下面,我们就给出一个表数据与Join组合方式的数量关系。
表数量 | 左深度树的数量 | 多路树的数量 |
1 | 1 | 1 |
2 | 2 | 2 |
3 | 6 | 12 |
4 | 24 | 120 |
5 | 120 | 1,680 |
6 | 720 | 30,240 |
7 | 5,040 | 665,280 |
8 | 40,320 | 17,297,280 |
9 | 362,880 | 518,918,400 |
10 | 3,628,800 | 17,643,225,600 |
11 | 39,916,800 | 670,442,572,800 |
12 | 479,001,600 | 28,158,588,057,600 |
很吓人吧!左深度树的数量基于是n!个(n的拉斐尔函数,n的阶乘,其中n是表的个数)。对于多路树,数量则是(2n–2)!/(n–1)!。
另外,需要记住的就是:上面还只是产生的执行计划的可能数量而言,对于其中的每一个执行计划,查询优化器还要去选择不同的物理操作和数据访问方法(例如,是进行Table Scan还是Index Scan还是Index Seek等),而这些再次乘以之前的数量,查询优化器的工作量可想而知。
最后一个问题是:查询优化器会对上面的所有的组合方式的成本进行估算吗?
答案是:不会!查询优化器会综合考虑很多的因素来决定。

