第三代分布式数据库(1)——踢球时代
十四届中国数据库技术大会(DTCC2023)很荣幸邀请到了李海翔老师分享他的《第三代分布式数据库》系列。此文是三篇文章的第一篇,在这篇文章中,李海翔老师总结了数据库技术的发展历程,并着重讲述了分布式数据库的发展历程。
2023年8月DTCC,分享了题为“第三代分布式数据库”的内容。其中,包括了三个方面的内容,如图1:
1. 对数据库技术的发展历程总结、重点是对分布式数据库的发展历程的总结。
2. 从总结中结合“创新”的话题进行思考,思考创新的源泉源自哪里?
3. 分享了第三代分布式数据库的3个重要特征、特征源起。

图1《第三代分布式数据库》内容大纲
一 数据库的历史告诉了我们什么
数据库发展了70年,涉及的技术和相关事件丰富多彩。如图2所示,一些主要的事件标识、引领了各种数据库数据技术产生、发展和繁荣。
在这70年中,分布式数据库随着数据库技术一同发展。总结历史,可以看到,分布式数据库走过了2个阶段。
1. 分布式数据库的2个阶段
第一代分布式数据库所处阶段,称为研究时代:这个时代是数据库、分布式数据库概念提出和原型实现阶段(20世纪60年代到90年代末),研究者们几乎并行地对单机数据库系统和分布式数据库系统进行了系统化的研究和探索(分布式数据库基于了大量的单机数据库系统的研究成果)。这个阶段的分布式数据库,以松耦合的方式,在同构或异构的单机数据库的基础上,诞生了分布式查询优化、分布式事务的2PC(跨机分布式事务,确保提交操作的原子性)等技术。其中,2PC技术解决了跨节点之间事务提交的原子性和部分情况下的数据一致性(不是所有的数据一致性的问题,只是一部分)的问题。
第一代分布式数据库以研究为主,未完全进入到大规模实用阶段。这个阶段,尚未解决数据的正确性(如不能知晓世界上有多少个数据异常等)、扩展性、可用性、事务一致性等重要问题。其中,2PC技术最为经典,其成为分布式事务技术的代名词,以至于21世纪的现在,多数人谈及分布式事务的时候,只知有2PC不知有其他重要技术。
第二代布式数据库所处阶段,称为海量数据时代:这个时代是实用化阶段(20世纪90年代到21世纪20年代初),分布式数据库真正进入一个实用阶段,这个阶段在数据量爆炸式增长的应用需求推动下,分布式数据库从理论进入到实践阶段,该阶段被理论和用户需求双重推动,使得分布式数据库进入真实地生产环节;典型的标志性技术/事件有三个,标志着分布式数据库系统成熟:
一是20世纪90年代初Paxos协议问世,使得单机时代主从复制技术在数据多副本的一致性方面获得理论层面的保证,基本解决了数据库系统高可用的难题,使得数据库系统具备了跨地域/跨物理节点级别的容灾能力;
二是20世纪90年代末CAP理论问世,使得分布式系统在一致性和可用性方面的关系/边界变得明朗(但不特别明晰),促进了分布式数据库系统在理论层面的进一步扩展和实践层面可落地的发展;
三是2012年,Google的Spanner系统面世,标志着前述Paxos和CAP理论在工程实践层面具备可行性,分布式事务的最强一致性(严格可串行化)可实现。
这三个典型的技术/事件,促使分布式事务型数据库系统进入实用阶段,因此诞生了一批分布式数据库系统。
这个阶段的产品,开始进入到大规模实用阶段。不足之处,在于未能100%解决数据的正确性(低于可串行化隔离级别的计算水平扩展能力已经具备),事务层面未能实现极致的水平扩展弹性,且更未能在极高性能背景下同时实现100%的数据的正确,因此数据库的数据正确性和高性能的问题尚未得到解决。
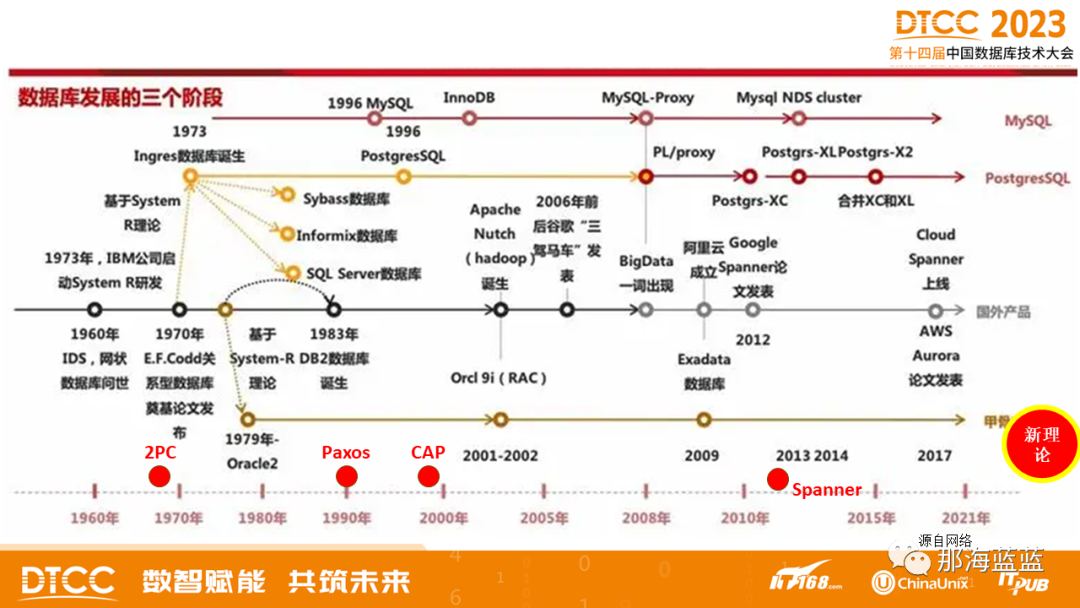
图2 数据库发展历史与分布式数据库前2个阶段的标志事件
2. 我们的问题与思考
目前,第二代分布式数据库已经日渐成熟,且有了较多的应用,那么,下一代数据库产品,长得会是什么样子?
为了讨论清楚下一代数据库的核心特征,我们深入思考了:数据库的根本是什么?是什么从数据库最深处最强烈地推动了数据库技术向前发展?
长期使用第一代和第二代数据库产品,长期被现有知识体系熏陶而迷醉,长期被现实环境包围而纵使有太多无奈也已不再。这或许是我们曾困惑之因?
迷雾中,不忘初心方得始终——我们可回顾事务型数据库的初衷与本质,我们会发现,纵使70年的长发展史,数据库居然未完美解决其最核心的几个问题!
“三高一易”(高可靠、高可用、高性能、易用性)是数据库的核心特征概括。但是,我们来回顾其发展历史,蓦然回首,骤然发现——数据库的基本问题:正确性、易用性——尚未完美解决。解决其基本问题正是数据库发展的核心动力。如图3所示。

图3 数据库之核心责任数据库却未能担当
第一个问题,数据的正确性:事务处理技术之所以重要,其核心就是在保障两点:在并发操作作用下,数据能正确性能被保证的同时,获得高的并发性能。
但是,数据正确性和数据库高性能在数据库层面完美解决了吗?答案是:没有!
在事务处理技术方面,分布式数据库的前两个时代,我们可以合并称之为“踢球给用户”时代,数据库(理论、内核)没有“把复杂留给自己、把简单交付用户”,所有的数据库产品都是一个半成品。
为什么这么说?————
(1)数据异常有多少个不清楚?ANSI-SQL只能枚举出4个,实则有文献报告出十几个(参考文献[1]更是报告了30+种,建议详细阅读参考文献[1],本系列文章的观点、术语和一些内容,源自该文)。数据异常是影响数据正确性的核心问题。
(2)数据库一致性的定义,有多种,每种之间定义不同,相差108000里。如理论层面用完整性约束表达一致性,实践层面却用可串行化理论“欲”确保并发调度是正取的、但可惜不能完全确保,真正在数据库引擎落地的实现中却采用冲突可串行化确保无数据异常(但也不能完全说清楚其是如何能保证完全没有数据异常的),但教科书也不明确讲出为什么这么做?语义的一致性和基于有向图的可串行化调度之间有什么关系呢?
(3)在分布式环境下,CAP的C和ACID的C遇到一起会发生什么事情,不能说明白,这导致所实现的分布式数据库从根本上而言存在有缺陷(读者可自行翻阅,第二代分布式数据库产品中,有哪些厂商会清晰地谈及自家产品在该问题上的处理技术?)。
(4)CAP虽然描述了在P发生下A和C的关系,但是不能细化到对时延有敏感的事务的时延上来。PACELC(Abadi提出,含义为:如果发生分区事件(P),那么如何在可用性(A)和一致性(C)间进行选择?否则(Else),即不发生分区事件,那么如何在延迟(L)和一致性(C)间进行选择?)。换句话说,共识协议解决了系统级高可用,可实现跨区容灾,但是事务级高可用问题该怎么解决?事务级高可用对用户非常有帮助,例如:在一个HTAP系统中,一个执行了三天三夜即将出结果的报表查询在最后执行的十秒内,网络分区事件发生了,这个报表事务是否应该回滚重做?
第二个问题,数据库的性能(和数据正确性):
数据库圈有一些“习惯成自然”的怪圈,使得我们的认知停留在一个错误的圈子里不自知,甚至还会觉得,自己所秉持的是正确的。
例如,常有人会说“数据库的隔离级别设置为RC足够了”!可是,为什么足够了呢?因为他们觉得RC级别下数据库性能好。
可是如图4左上部所示,存在一个死循环:用户希望数据库性能高(成本低),于是开发者会把应用的隔离级别设置为RC,可是用户尤其是金融保险证券电信等用户又期望保证数据的正确性,于是开发者不得不在SQL语句中加入“Select…For Update”以确保数据的正确性,但是,此举会导致数据库系统性能下降严重,如图4在TPC-C和YCSB场景下测试结果表明,用户主动加锁的方式会导致数据库系统性能下降严重。
长期使用Oracle等系统,很多人已经习惯与Oracle式思维而陷入Oracle式陷阱,这其实严重背离了数据库的初衷和本源。
所以,我们是不是可以很朴实地期望:数据库系统既能100%地保证数据正确性又能具备最高性能?
如果这一天来临,是不是开发者开发变得容易(不用分析应用场景是否会触发数据不一致、不用担心编程有加锁后的死锁遗留),应用拥有者能完全无负担地去推广应用(不用担心数据会有任何差错,让数据库完全保证金融交易分毫不差)?

图4 用户在应用中主动加锁导致数据库性能下降严重
第三个问题,数据库的易用性:用户的期望和现实完全背离。
数据库的易用性,更是一个巨大的现实问题。用户使用任何一个软件,都期望软件极其易用甚至是傻瓜式。可是,数据库能满足傻瓜式这样的基本需求不?不能!
数据库的易用性极差,表现在很多方面,如图3右部分:
1. 数据库需要专业的DBA管理+运维,高昂的成本,使得数据库不能普及;
2. 数据库需要专业的设计库表结构(需要熟悉ER模型、范式定义);
3. 开发者需要深厚的专业的知识,需要知道如何设置隔离级别,需要知道哪些情况下会出什么数据不一致性,需要知道何时主动加锁,需要知道SQL语句的写法、复杂SQL如何写更高效,需要知道如何配置各种参数…;
4. 面试者需要广且深的数据库相关知识…学习一些未被经典教科书讲明白的知识,难上加难。
读者会深深觉得,实际上远不只是这些。数据库的易用性差,示例几乎数不胜数,是不?!
小结:我们认为,第二代分布式数据库系统已经成型;前两代的发展虽然历尽艰辛,但发展初期一直处于懵懂状态,数据库技术在开拓式思维的基础上不断被探索和前进,但是,他们都缺乏合理的预先设计(预定义特征、有目标的研发)。
现在,是时候请用户把球回传给数据库研发人员了(既要又要、有预期有目标的时代来临)。
在数据库技术70+年的发展中,当我们积累了较多的经验后,我们将有能力有预期地来预测第三代分布式数据库的核心需求、特征,以此为指引,向下一代产品迈进。
凡事预则立不预则废,第三代分布式数据库的研发将建立在“先做预期后推进研发”的研发模式中,懵懂不知、黑暗摸索的时代将一去不返!

