SIGMOD2023:技术达人必须了解的数据库研究及前沿趋势
作为数据库领域的“风向标”,SIGMOD会议拥有40年发展历史,每年为数据库领域提供大量高质量的研究论文和研究成果。可以说,SIGMOD代表行业最高水平,具有重要的学术价值和行业引导意义。那么,SIGMOD2023展示了数据库领域的哪些新进展、新方向?腾讯云数据库近期举办了《2023 SIGMOD 论文解读会》,针对机器学习、图计算、大模型、新硬件、数据库系统等前沿技术,邀请业内知名教授、学者进行了干货分享!
1、 关于事务处理、搜索与数据分析研究方向
在SIGMOD国际会议上,每年都会有大量高质量论文提交,但由于审核较严格,只有少量优秀的论文能够被录取和展示,近十年的接受率保持在20%左右。我国学者对SIGMOD的认可度很高,很多有代表性的论文为行业发展带来极大的参考价值。从2023年SIGMOD论文发表方向来看,和事务处理、向量数据库相关的话题,成为理论研究的重要方向之一。深圳大学特聘教授 秦建斌 老师,一直在研究数据库系统和数据质量相关的内容,其中与向量数据库关系密切的相似性搜索、高维向量等内容,都是研究重点。
1) 事务处理
推荐主题:
l Transaction Scheduling :From Conflicts to Runtime Conflicts


多线程事务调度算法研究:
这是一篇来自于深圳计算科学研究院和爱丁堡大学合作的一篇论文,这篇论文是针对于大量并发事务需求做的多线程事务调度算法的研究。论文核心思想是,在多线程高吞吐量、高并发事务处理当中,现有的调度或者说叫事务划分的策略,会把有冲突的策略尽量划分到同一个区块里面,在一个线程里面去完成,由于T1、T2、T3之间冲突量比较大,会划分到一个区块里,另外一个线程会完成冲突率比较大的事务,利用并发控制(CC)的方法来完成并发控制。
l Polaris:Enabling Transaction Priority in Optimistic Concurrency Control
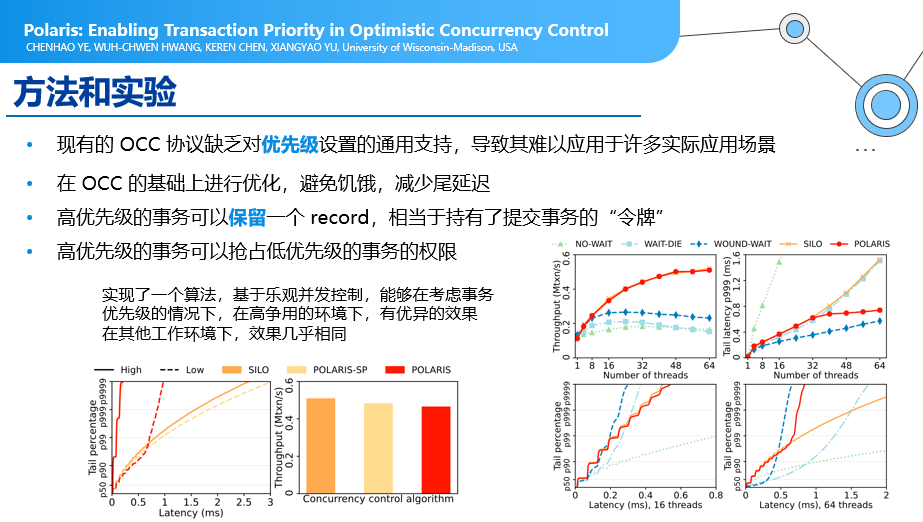
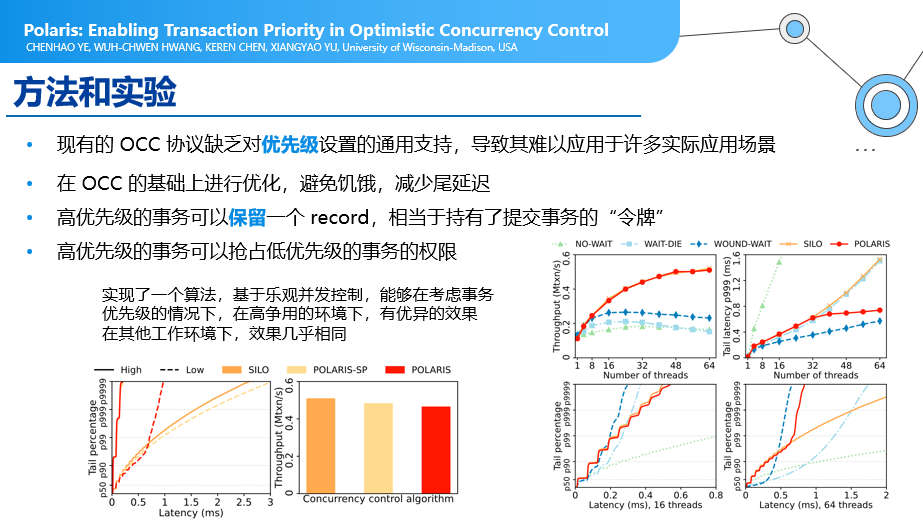
并行处理问题:
在现有高并发事务情况下,一般会使用OCC协议这种策略,但OCC协议缺乏对优先级设置的通用支持,导致其难以应用于许多实际应用场景。在OCC协议下,需要在事务执行结束的时候才进行正确性检查,如果事情结束的时候发现冲突,可能会导致一些事务频繁的回滚,得不到更好的执行。所以,本文作者的优化方向是,在已有OCC并发控制协议下,加入了一些“令牌”的方式,来进行事务优先级的控制,比如:一个事务在考虑到它的重要程度或者在多次被回滚的情况下,会得到更高的优先级。这是一个非常有意思的方法,在一些比较极端的尾部延迟,时延在99%以上比较慢的情况下,会有效改善事务提交的成功率。
l One-shot Garbage Collection for In-memory OLTP through Temporality-aware Version Storage
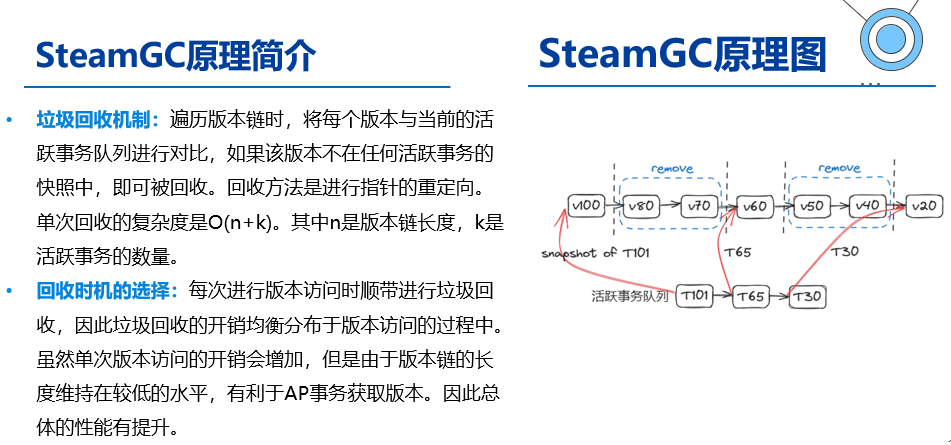
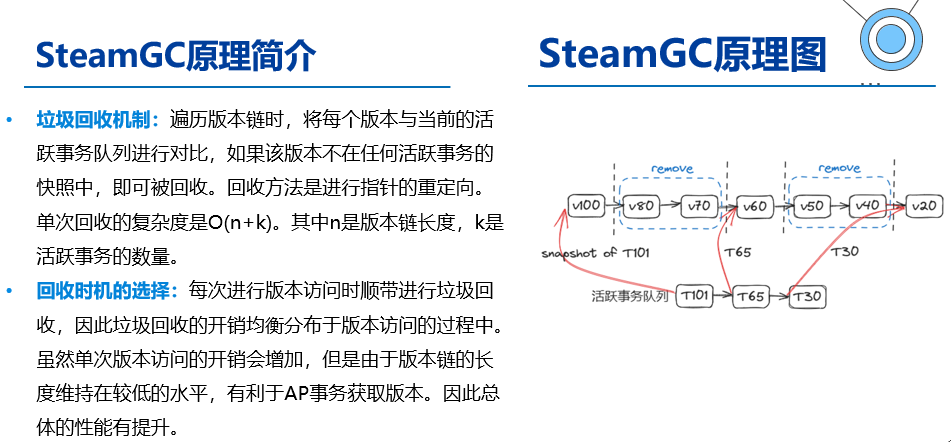
基于steamGC的思想进行改进:
steamGC在理想情况下能够将所有记录的版本链长度控制在当前所有所有活跃事务数量M之下。但是steamGC存在如下缺陷:steamGC会针对每个记录进行垃圾回收,因此会产生大量的随机访问,影响TP引擎的性能。oneshotGC则提出基于分区的版本划分,致力于一次回收一整个分区内的版本,以此减少随机访问。
2) 估计和搜索
推荐主题:
l When Tree Meets Hash: Reducing Random Reads for Index Structures on Persistent Memories


对基数树中的每个节点使用可扩展哈希:
这种设计允许我们有一个相对较大的基数树的扇出(fanout),以保持树的高度较小,并且还实现了节点内的恒定时间查找。使用可扩展哈希还允许在插入和更新期间进行增量节点修改,而不会出现过多的写操作。通过在每个节点的哈希表中的键之间强制部分排序,而不会引入更多的哈希冲突,可以高效且健壮地处理范围查询。经典的可扩展哈希通过LSB(桶间/桶内无序)来索引桶,这不利于范围查询,所以此处的哈希表应用了类似CCEH的分层结构,通过在目录和桶中间引入segment层(由MSB索引,段间有序段内无序)达到支持范围查询的目的。
l InfiniFilter: Expanding Filters to Infinity and Beyond
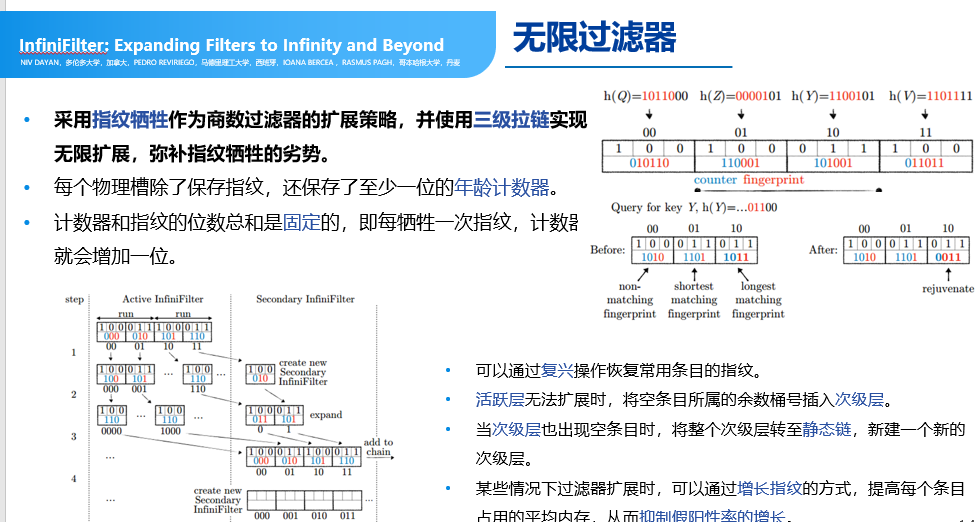

无限过滤器:
我们可以把过滤器可以看成类似于用来做过滤用的数据结构,过滤器或者这种数据结构是为了能够快速让用户,或者让系统能查询什么样的数据已经访问了,什么样的数据可能存在,什么样的数据不存在。为商数过滤器设计了一个无限扩张的过滤器之后,等于系统具备了无限扩展的能力。主要思想是,通过保留哈希值的商数,也就是哈希值上面那半段,使得上面半段做指纹的比对,保留上半段可以帮助商数过滤器进行扩展,在数据比较大的时候可以把哈希表往外扩。
l Pea Hash: A Performant Extendible Adaptive Hashing Index
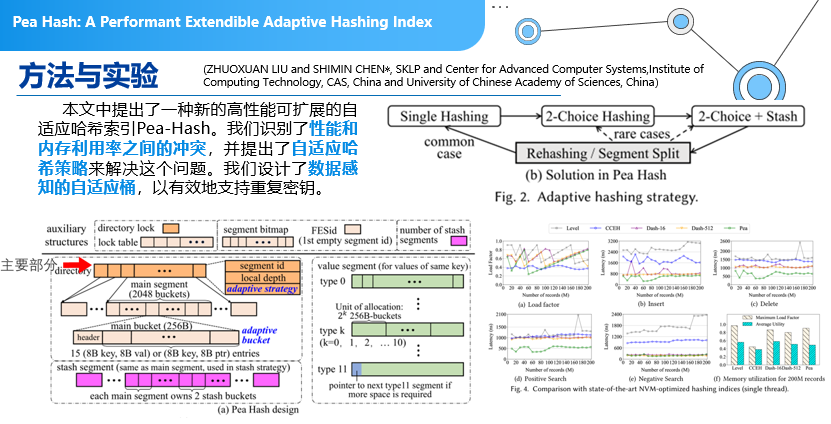
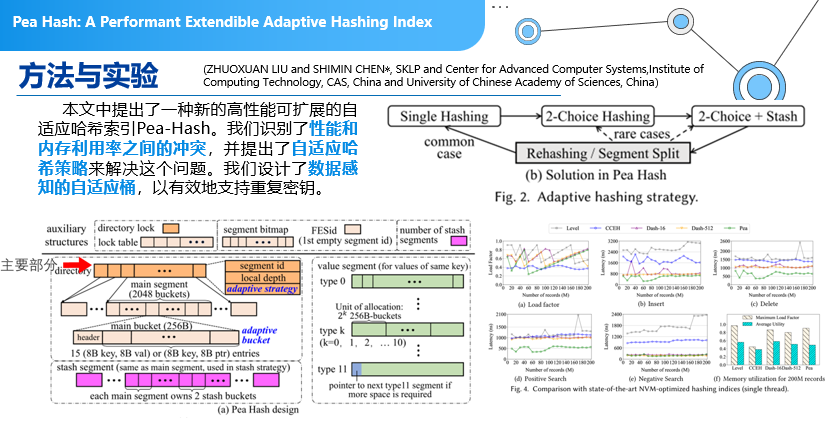
哈希扩展:
这是来自中科院的一篇关于哈希扩展相关的论文,但实现方式不一样。通常,我们在设计一个哈希表的时候,不知道需要设计多宽,希望哈希表能够自动去扩展。自动扩展的过程中有两种扩展:一种是存储空间的扩展;另外一个是哈希函数的扩展。本文主要思想是,引入了动态的哈希,当你的冲突并不是非常多的时候,只要有一个哈希函数就可以了,冲突比较大的时候,数据量比较大的时候,会采用2-Choise Hashing,用两个哈希函数来做一个选择。更极端的情况下,采用2-Choise Hashing加上其他Stash技术来做动态可扩展。
l High-Dimensional Approximate Nearest Neighbor Search: withReliable and Efficient Distance Comparison


高维向量搜索:
我们在做高维向量搜索的时候,会获得大量信息,也需要做一些比对,当有几千维的高维向量,拿真实的场景和数据进行对比的时候,算真实结果的时候也会耗费很多时间,而基于ADSampling是递增计算距离的方法,就不用去完全比对。在ADSampling方法中,只要查询算法有欧式空间距离计算的环节,就可以采用ADSampling计算。一般先用随机正交矩阵对整个欧式空间进行随机旋转,之后再从头往后选取维度进行dis'的计算,以实现维度的抽取。
l LiteHST: A Tree Embedding based Method for Similarity Search


向量空间工作:
在已有比较知名的HST数据结构上,tree embedding是树状的数据结构,上面进行了一些优化,一个是对保存结构做了优化,另外就是保存了更多的信息,用于更深入的剪枝,实验效果非常不错。
3) 数据分析和数据科学流程
l DiffPrep: Differentiable Data Preprocessing Pipeline Search for Learning over Tabular Data
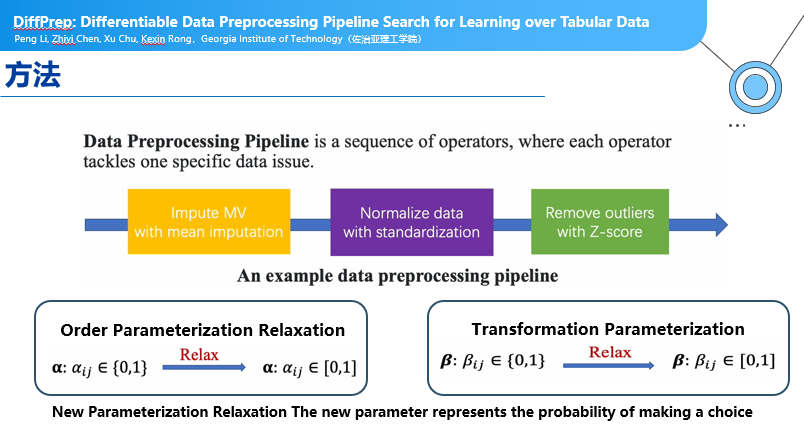

参数可调的预处理的pipeline:
在一些机器学习任务中,预处理过程有可能占用大量时间,同时,预处理这个过程并没有真正参与到后面的机器学习参数学习的过程。Diffprep方法,是把一些预处理的工作标准化,再把标准化之后的预处理工作参数化,这种可以参数化的预处理的pipeline,可以直接参与到后面的机器学习过程中,为机器学习应用提供了一个很好的工具。
l AutoOD: Automatic Outlier Detection
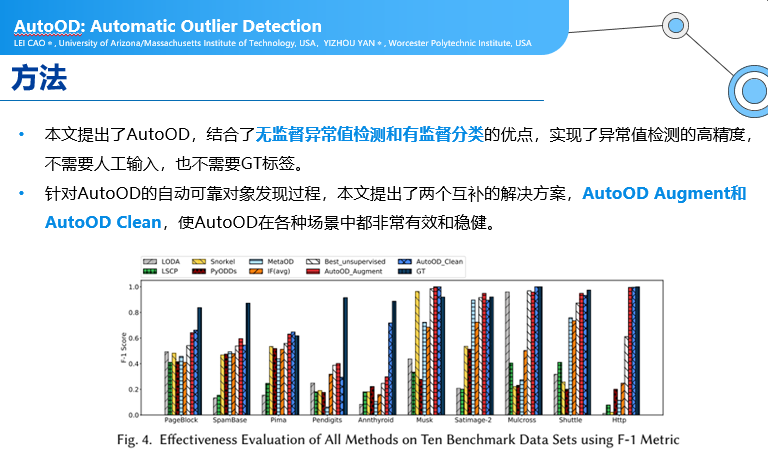
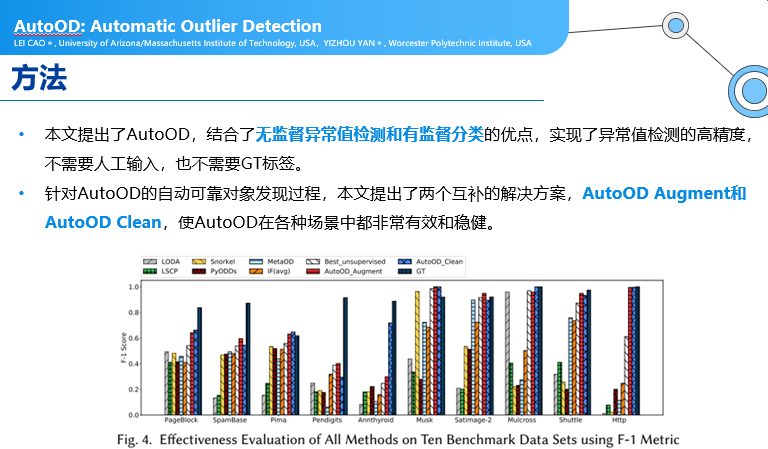
异常值检测:
很多人在做专用的异常值检测,当来了一个新的数据集,遇到新问题的时候,检测要重新训练、重新标注,本文提供了能够自动化跟人交互的方式下,自动化的一些方法。
l HAIPipe: Combining Human-generated and Machine-generated Pipelines for Data Preparation


将HI管道与AI管道相结合:
本文的观点是,机器学习学出来的管道和人为写出来的管道有自己的优劣性,这个论文提出强化学习的方法,把人工写的广告和机器学习学出来的广告相结合来提升性能。
除了事务处理、搜索与数据分析方向,GitTable大型语料库、利用表格的列类型和列关系来查找可连接表、混合数据匹配模型等话题也值得重点关注。通过对大量论文的梳理,秦建斌老师还发现:人工智能与数据库集成会持续是一个重要方向,超过15%的论文与此相关,表明将人工智能技术应用于查询优化、自动索引等方面有很大潜力;同时,云原生数据库会越来越受关注,近10%的论文探讨了Serverless、分布式系统等云计算话题,说明数据库向云平台迁移是重要趋势。
2、新硬件为强大算力加速
当人工智能与数据库深度集成,关于硬件的研究是行业关注重点。
南方科技大学的助理教授 唐博 老师,主要分享了他们团队中稿件的三个方向:第一,基于Cardinality Estimation算法提出来一个端到端的加速技术;第二,如何基于Cardinality Estimation、PageRank这样的算法做大图的Visualization;第三,传统算法问题,比如:在有坡度的平面上怎么去找任意两点之间的最短距离,我们可以通过建立一个EAR-Oracle的方式去做这件事。
推荐主题及介绍:
l Distributed GPU Joins on Fast RDMA-capable Networks
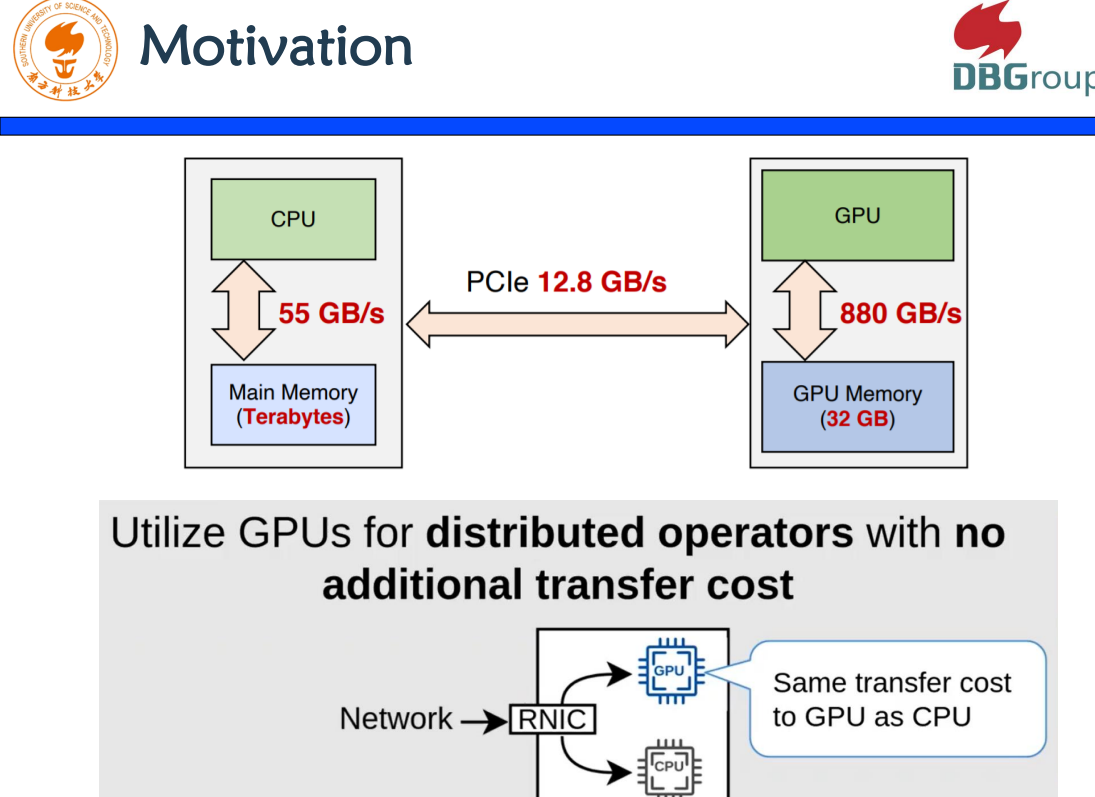
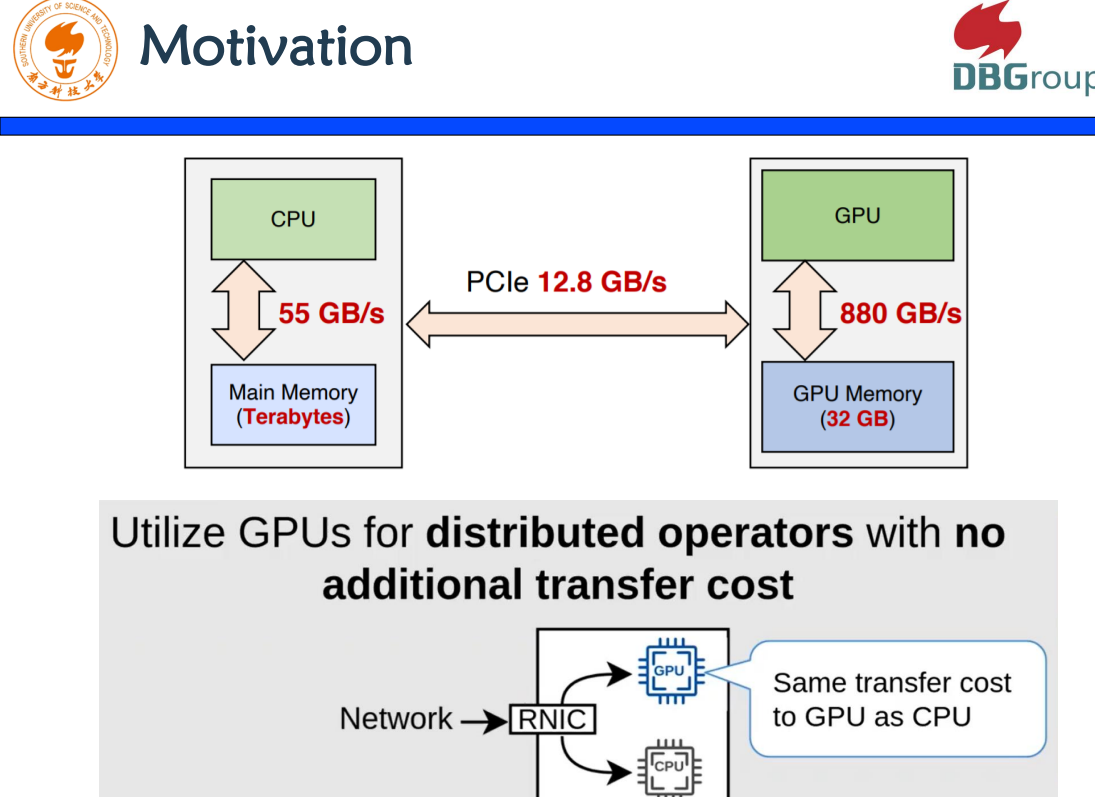
整个研究的目的是什么?关键词就是GPU!我们可以看到,CPU和GPU的性能特征是,CPU的内存很大,GPU的内存很小。CPU和GPU之间如果要做数据传输,需要通过PCIE,而PCIE很大,800GB和55GB,CPU和GPU之间的PCIe是12GB,这是一个瓶颈。同时,GPU的内存有限,当你要去用GPU的时候,怎么样快速执行。本文的解决方案是,把所有工作全部在CPU上做完,通过单边的RDMA,把数据传到GPU上去,在GPU上做Join的操作,有效解决了内存不足的问题。
l Design Guidelines for Correct, Efficient, and Scalable Synchronization using One Sided RDMA
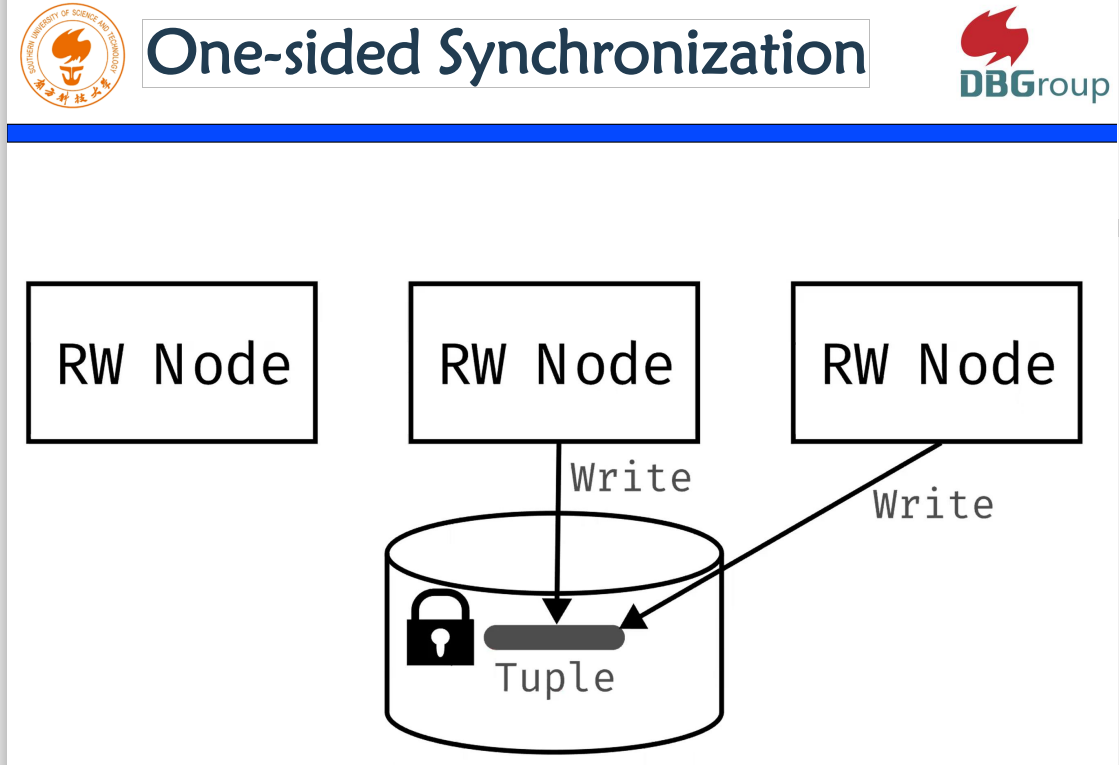
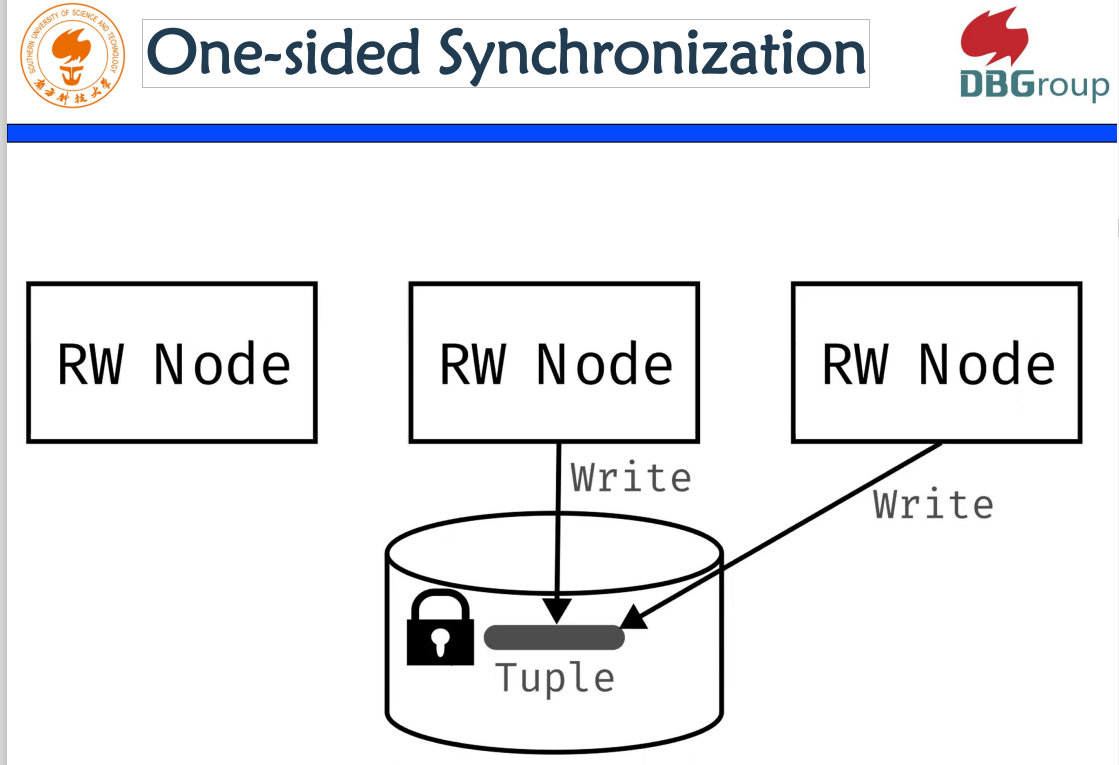
如果我们的机器是建立在云原生上面,建立在分段解耦的架构上面,分段解耦之后有网络层用到RBMA去做内存访问,内存下降之后,我们怎么样去做一个正确的、高效和可扩充的同步协议,应该是年轻一代应该研究的方向。
l Selection Pushdown in Column Stores using Bit Manipulation Instructions
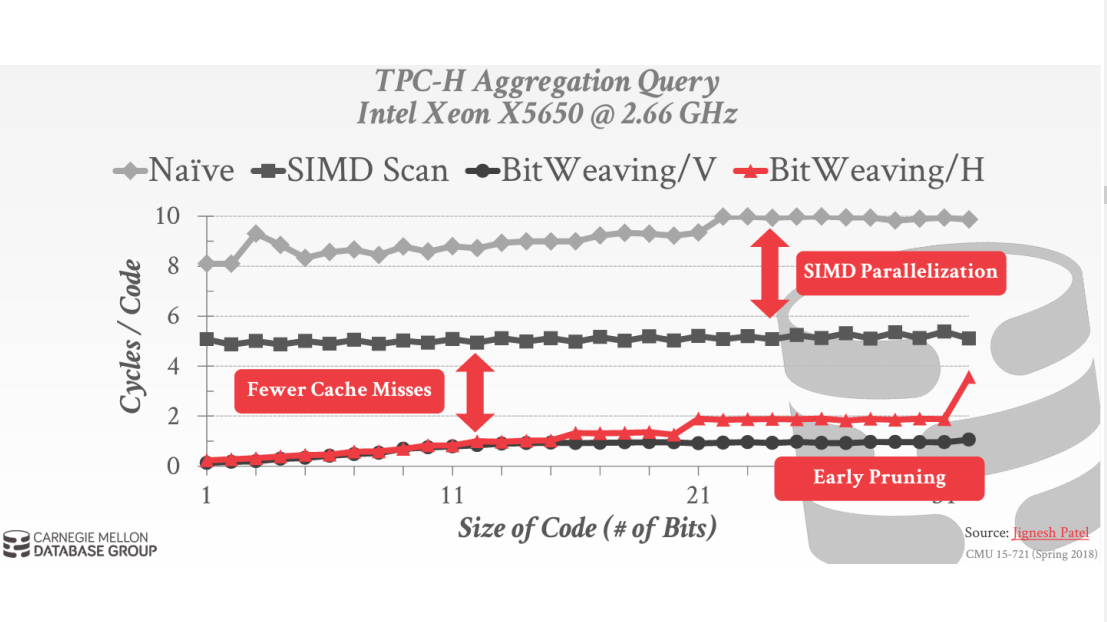
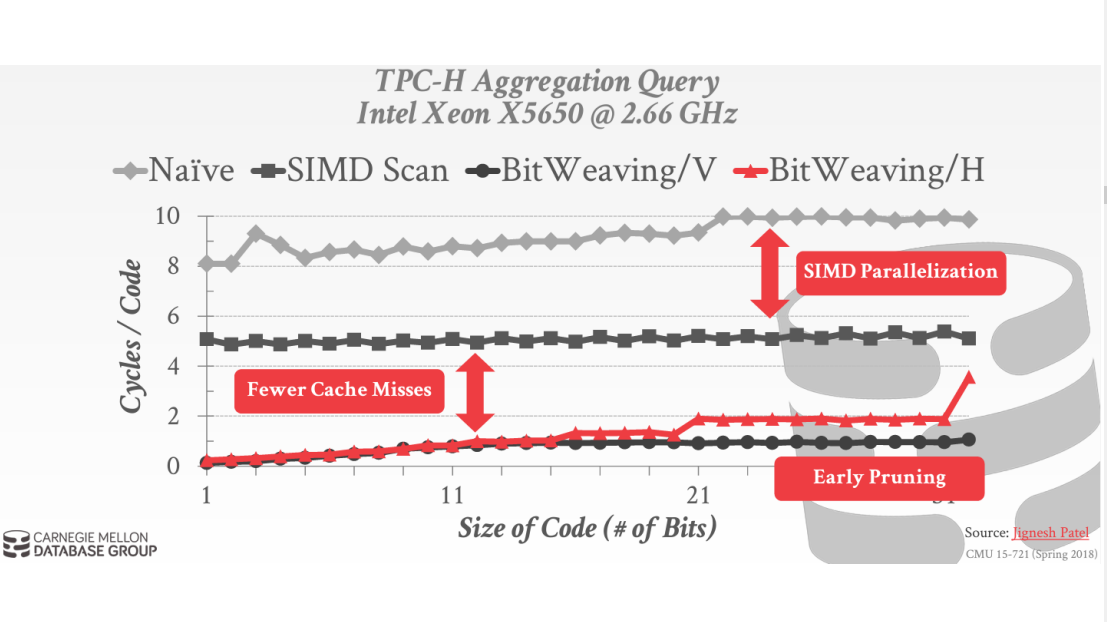
本篇论文出自微软研究院的一个专家,他用BMI Instructions去做Selection Pushdown,使得性能加速。他在2013年做过一次,类似于把Bitweaving拿出来操作;10年后,这个人又把英特尔用的BMI,也就是原本用的Software的比较,用BMI来做,在两种CPU上面进行操作的时候,性能有很大的提升。
l Design and Analysis of a Processing-in-DIMM Join Algorithm: A Case Study
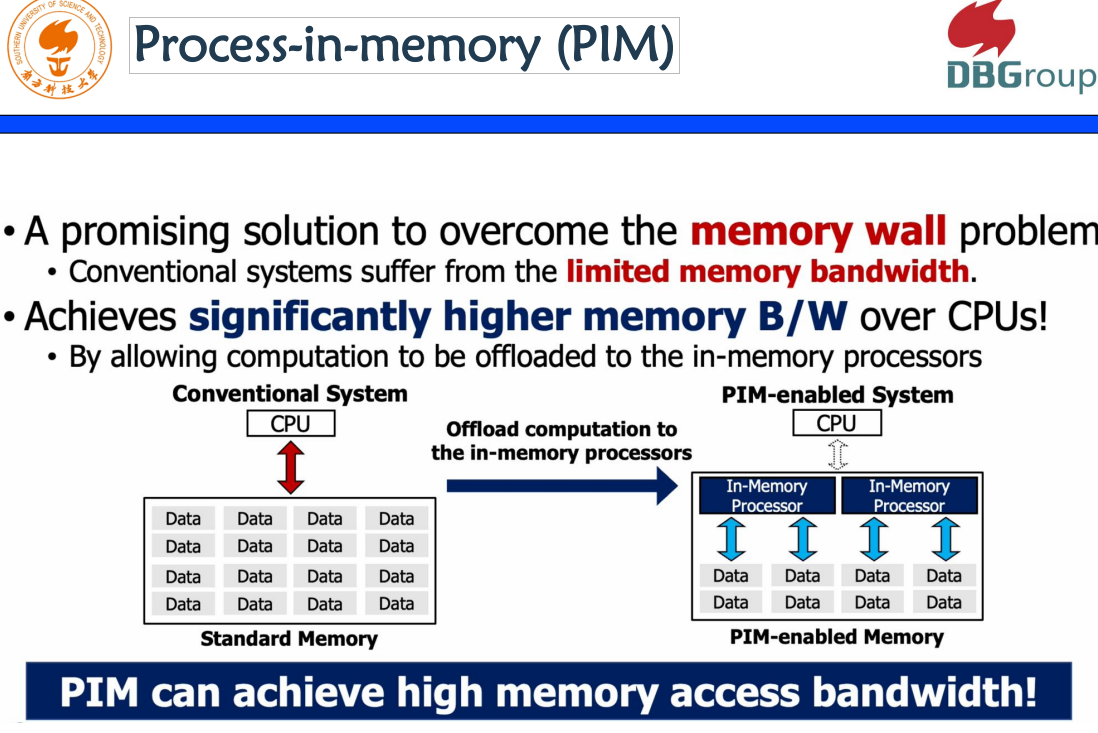
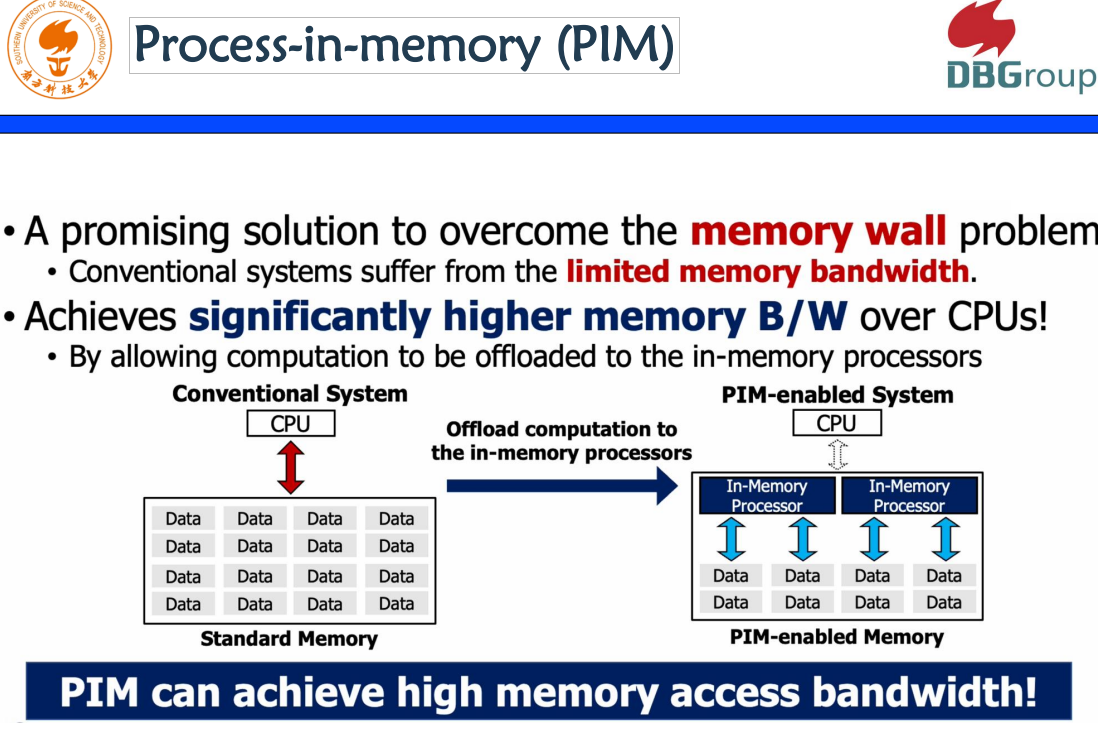
这是一篇来自韩国团队的论文,是一个关于新奇硬件的研究。毋庸置疑,Join在RDBMS中是一个特别重要的操作,而Join High memory access bandwidth是加速join的核心问题或者核心机制,他提出在现有系统里面data和CPU的处理,其实是受了memory wall的影响,如果在memory里面有PIM,PIM就是Process-in-memory这样的硬件的话,可以把数据在PIM里面先处理,再拿到CPU上面去。
l Ready to Leap (by Co-Design)? Join Order Optimisation on Quantum Hardware
这是一篇来自超级大佬的脑洞大开,有点类似天外飞仙的感觉。他通过Co-Design,把Join Order的Optimisation和Quantum Hardware联系起来,把这个Join on Quantum Hardware做了很快的一些转换,变成mixed integer linear program的问题。
除了端到端的加速技术和很多查询优化、算法优化等工作,还有Graph方向也就是研究重点,比如:基于PageRank算法做大图的Visualization等等,都是非常有意思的话题。
3、 FlexMoE机器学习优化大模型训练
在SIGMOD2023会议上,很多人在关注数据管理和机器学习相关工作,比如:如何利用机器学习以及数据管理的思路去优化大模型的训练系统。
卡耐基梅隆的博士后研究员 苗旭鹏,主要介绍了两个部分的工作:第一部分,在以数据为中心的MLSys方面的最新进展;第二部分,关于MLSys研究趋势的看法以及被接受论文的案例研究。
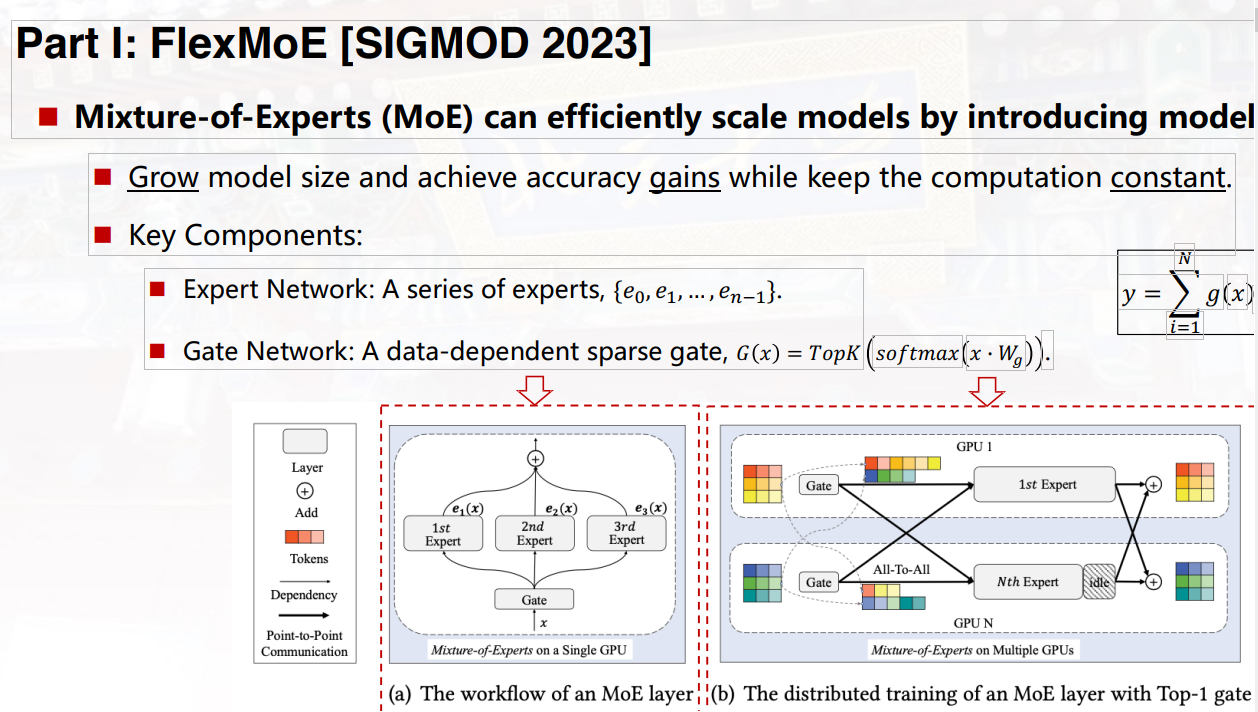
以FlexMoE为例,这是一个通过动态设备放置器缩放大规模稀疏预训练模型的训练。FlexMoE是针对稀疏的预训练模型,也就是MoE这种多专家混合模型进行动态资源放置的优化工作,该工作由北京大学软件研究院,CMU,还有北京智源等单位的作者共同完成。
在过去这一年里,大模型变得越来越火,目前业界比较领先的transformer模型,大概在每两年750倍这样的速度进行增长,这样的模型规模增长也给底层GPU的硬件加速器带来非常大的压力,不管在计算和存储上都面临严重的瓶颈。
MoE模型,是由谷歌提出的一种非常友好的具备很好的可扩展性的大模型,因为在原来稠密的transformer模型基础之上引入了稀疏特性,这也就导致随着模型规模的增长,我们可以获取一定模型效果的提升,但同时由于稀疏性可以保证计算量维持在常量水平。尽管MoE模型很容易覆盖到比较大的规模,但是现在的系统并不是非常适合进行这样模型的训练。一个主要的挑战就是,MoE模型当中具有不均衡和动态的负载变化,从而导致我们GPU的利用率可能比较低。现有的系统,比如说像开源的DeepSpeed系统,通常采用一些系统友好的解决方案,但是可能会影响最终模型的效果。
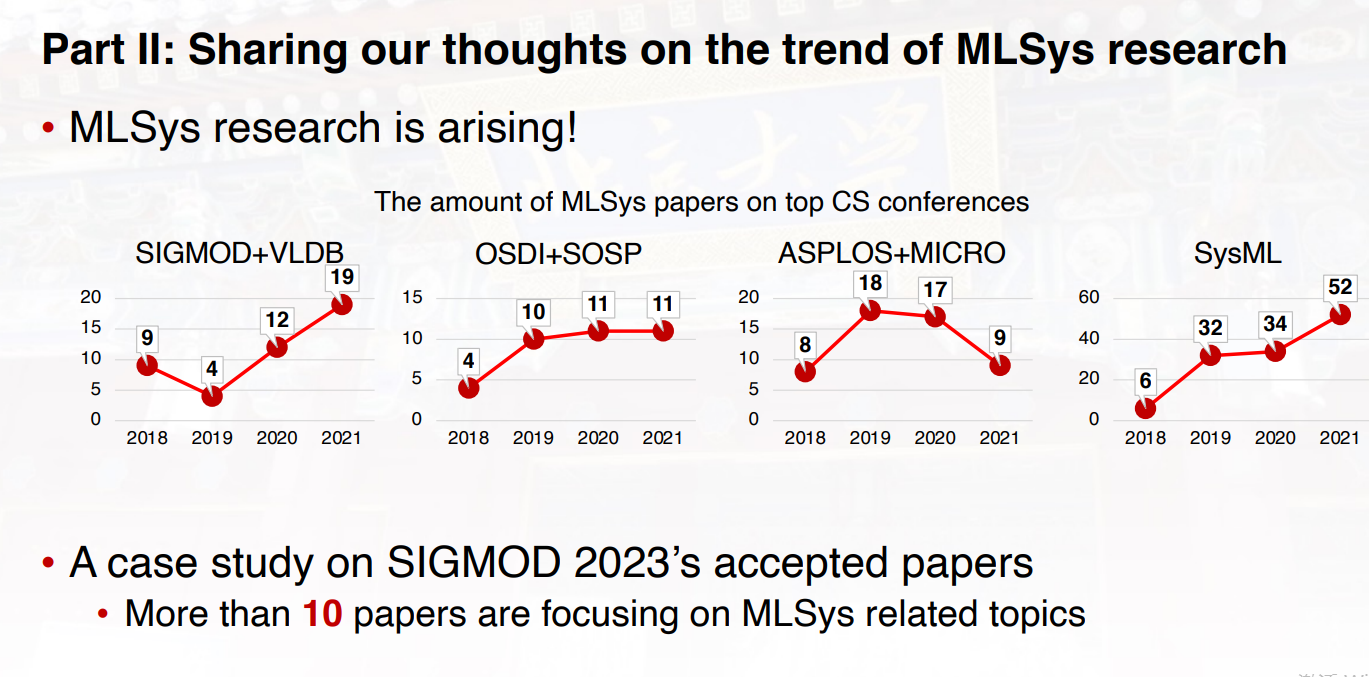
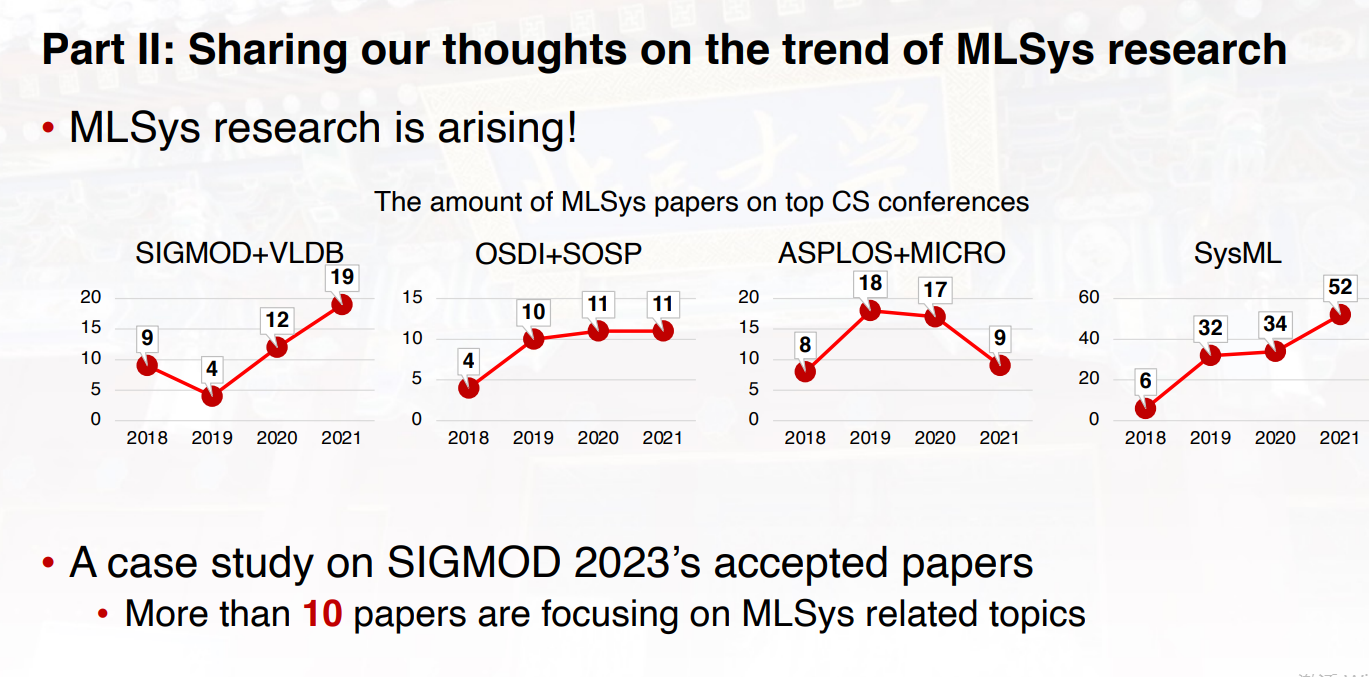
一类方法是,去给每个专家网络能够接收的最大token设置一个容量的上限,但是这也会导致额外的问题,当我们的输入数据超过专家所能承载的容量之后,这些数据会被丢弃掉。最后,优化的策略是,主要是针对MoE模型训练当中不平衡和动态变化的负载特性进行优化,提出细粒度基于expert进行复制和调整的解决方案,通过动态管理可以使得专家到GPU设备的映射关系进行一些优化,从而降低不同GPU之间的通信,使得我们的端到端的训练效率得到显著的提升。
4、图数据管理和挖掘成为重要课题
在香港中文大学深圳校区的 方一向 教授看来,图数据非常普遍,在DBLP文献网络、生物蛋白质网络,知识图谱领域,都是图数据诞生的重要领域。图数据作为典型的大数据,具有“三维”特点,所以围绕大规模图数据这些年的研究,趋之若鹜。在SIGMOD2023,有599篇投稿,最后收了171篇,大概有90篇论文是graph相关方向。分别是:搜索与挖掘、模式子图匹配、还有路径、可达性以及连通性,包括图计算的系统、图表达学习、随机游走、知识图谱、Diffusion and Propagation等等。
推荐主题:
1)图搜索、图挖掘
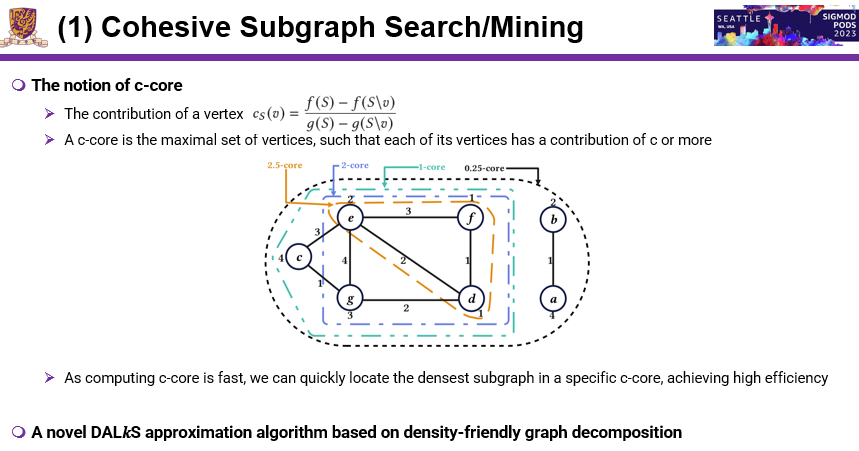
对这个课题研究已有40多年,针对密度的定义,最原始的密度定义就是边数除以点数。比如:一个密度最大的图,由于子图的个数是指数级爆炸的,所以这个问题求解起来是代价非常高,后面40年来,很多人都在研究,其中各种各样的密度定义还有不同的算法。本文发现,已有算法有一个很大的缺点,很少有算法能够支持任意不同的密度,而基于用c-core来解这个问题,可以解决传统方法带来的挑战。
2)一种基于目标模式的子图匹配
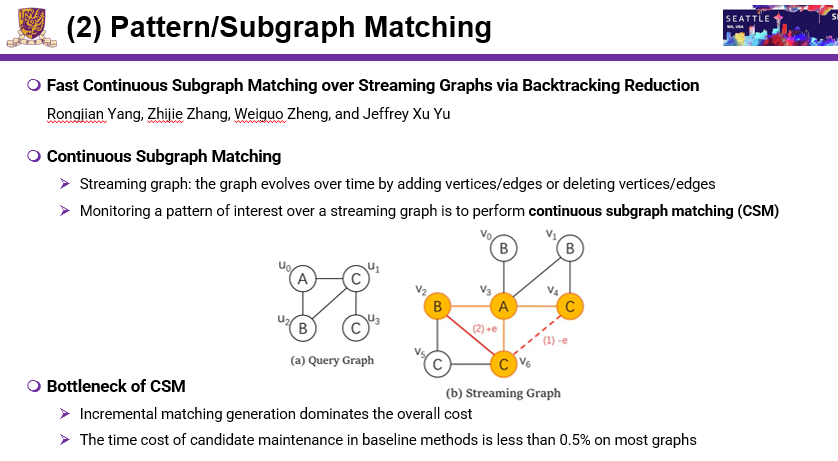
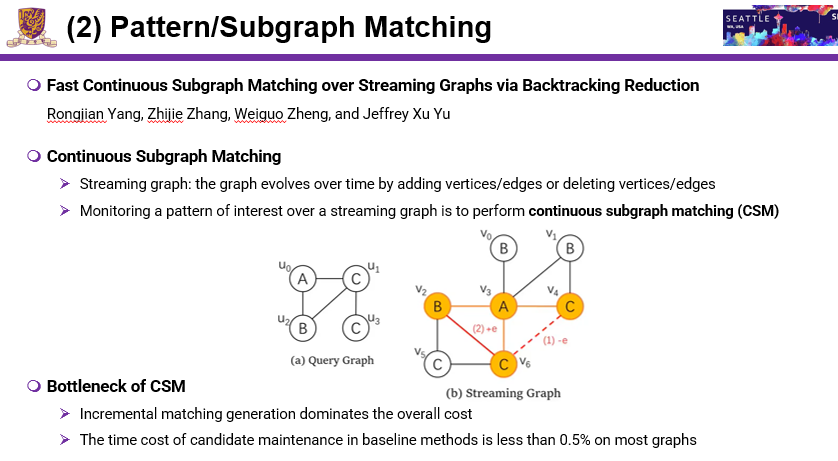
随着图的变化,match也会发生改变,怎么快速找到变化的match,这就是本文的关键点。本文研究主要分两个方向:第一,找一些候选集;第二,增量式的产生match。第一步可以找到candidate maintenance结果存储在哪,随着边的参数删除,就会把结果repot出来。Incremetal match generation dominates the oveall cost是第二步,第一步通常只占了0.5%,甚至更小。这篇论文主要思路就是说提出新的index,index尽可能少,基于index可以形成一个快速的incremental matching算法。
3)可达性、连接性和最短路径
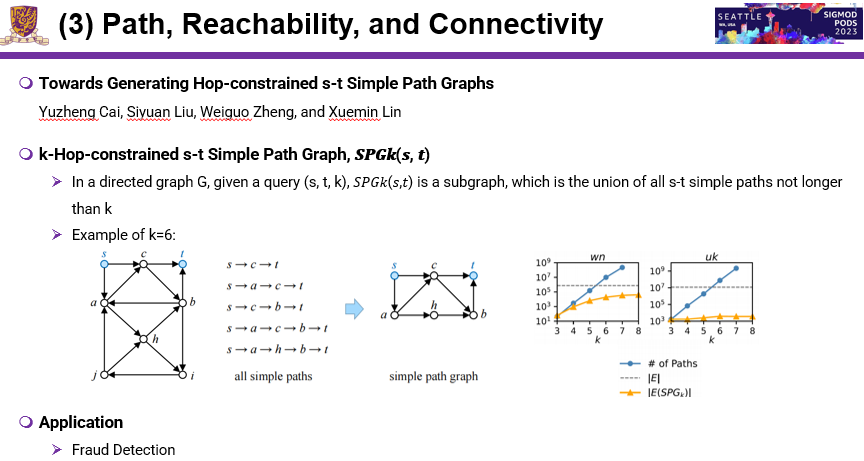

这篇论文提出一个概念叫k-hop constrained s-t Simple Path Graph,一个Graph包括所有s-t simple path,这个问题是第一次被提出来,它可以包含所有s-t simple path。有了这个方法之后,其他操作就变得非常简单了。
总结:
通过SIGMOD2023干货解析,让我们更加清楚地看到,诸多热点技术背后,已不只是系统性的研究。不管是向量数据库、机器学习、新硬件还是图,已经有一些前沿实践,以及技术路线方案,让我们永葆技术热情,始终屹立于时代之巅。期待SIGMOD2024会更精彩,会有更多来自中国的优秀研究项目,在业界脱颖而出。

