B 站基于 Iceberg 湖仓一体优化实践及智能化管理平台的助力
本文根据向阿鲲在【第十三届中国数据库技术大会(DTCC2022)】线上演讲内容整理而成。
讲师介绍

【嘉宾介绍】哔哩哔哩 OLAP 资深开发工程师,十多年软件行业从业经验,四年多大数据 OLAP 方向研发经验,先后在唯品会、B 站从事大数据 OLAP 方向的研发工作,目前主要负责B站OLAP平台,湖仓一体方向:Iceberg 内核研发、优化探索实践,智能化管理平台搭建、以及业务接入支持等相关工作。
本文摘要:本文整理自向阿鲲在DTCC2022大会上关于“B站基于Iceberg湖仓一体优化实践及智能化管理平台的助力”的主题演讲,主要介绍了Iceberg 湖仓一体项目在B站的落地实践,Iceberg 湖仓一体的内核优化,智能化管理平台的背景、意义与实践,以及未来展望。
分享大纲:
1、湖仓一体项目在 B 站 OLAP 平台的落地实践
2、基于 Iceberg 湖仓一体内核优化
3、智能化管理平台 Magnus
4、未来规划
以下为演讲正文:
湖仓一体项目在 B 站 OLAP 平台的落地实践
为什么引入湖仓一体?
第一部分先简单介绍一下B站湖仓一体项目的背景。下图是我们早期数据服务架构,借此来展开为什么会引入湖仓一体。
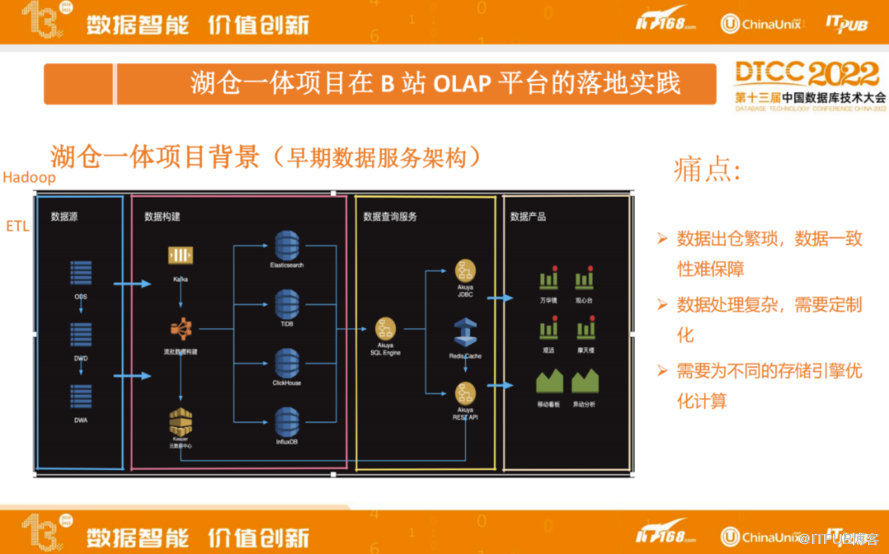
先介绍一下基础信息:在B站,大数据平台主要依托 Hadoop生态。我们看一下架构图的左侧,数据源经过 ETL 会把数据 load到不同的数据库引擎,像 ES、TiDB,ClickHouse、InfluxDB,以及HBase 等。然后通过一个统一的查询服务对接不同的数据库引擎,为不同的数据产品提供查询服务。这样一套架构会存在一些问题:
首先数据出仓繁琐,数据一致性很难保障,因为同一份数据可能存在不同的存储系统里面。二是数据处理复杂,需要定制化。此外,为了提高查询性能,需要为不同的存储引擎优化计算。
引入湖仓一体架构
针对以上痛点,B站引入了湖仓一体架构,并启动了湖仓一体项目。湖仓一体项目是在Hadoop生态上引入了Iceberg组件,通过在Iceberg组件上的一系列优化,在拥有数据湖灵活性的同时,打造了一套高性能的数仓的体验。

湖仓一体的数据流转图如上,左边是数据采集,目前B站的数据来源主要有 APP 埋点数据,MySQL业务数据,服务 log 日志等。通过公司内部统一的传输服务Lancer 进行数据分发,主要分两条链路:
一、通过Flink近实时地写 Iceberg 表,默认 5 分钟一个checkpoint。另外一条链路是天级或者小时级,落入到Iceberg表。Iceberg表无论在ODS、DWS、DWD的哪一层,都可以根据用户需求对外直接提供服务,目前最多的业务场景是使用 DWD层明细层数据直接对外提供服务。
数据导入后,会由智能化管理平台 Magnus,后台进行异步地数据组织优化。
数据分析侧:通过统一的计算引擎Trino作为查询的统一入口,同时也引入了 Alluxio作为缓存加速,以及保证查询的稳定性。
对性能有极致需求的场景,我们会将Iceberg表的数据出仓到ClickHouse,但是整体上用户可以直接基于Iceberg表进行OLAP查询分析。
湖仓一体的架构有不少优势,解决了此前数据服务架构的很多痛点。首先数据不用出仓,避免了数据重复存储。其次,大数据可以添加索引,支持毫秒级/秒级查询能力,满足基本取数场景。再者,从数据处理到取数过程大大缩短,数据处理也就更加高效了。同时,支持数据增量 update,支持事务,能对接更多业务场景。
目前湖仓一体项目在 B 站 OLAP 平台的落地场景主要有数据服务(取数服务)、ABTest 实验平台、BI 报表、标签人群圈选、日志检索等。如取数服务,主要对接公司的运营后台、数据产品(万华镜、观星台、Boss 看板等),以及OLAP多维分析场景。计算引擎Trino的单集群QPS峰值可以达到 300 QPS,数据产品万华镜目前的平均查询耗时大概在 200 毫秒。
基于 Iceberg 湖仓一体的内核优化
数据组织排序
Iceberg提供了文件级别元数据,像manifest 文件索引了所有的数据文件,并保存了数据文件的一些元信息,如数据文件路径、具体有哪些列,以及每个列的Min/Max值等。计算引擎可以利用Iceberg提供的文件级别元信息进行高效查询过滤。
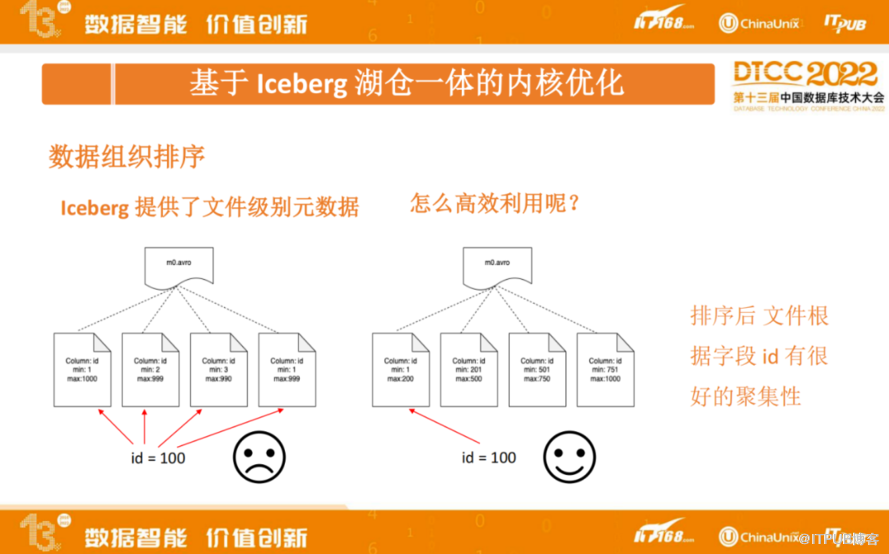
假如不对数据进行任何优化,直接利用Iceberg提供的元数据:字段在文件内的Min/Max值。如左上图,存在 column: Id,它的Min/Max 值在所有文件内都是比较分散的,如果通过id = 100 做过滤,由于每个文件的跨度都比较大,都可能包含100这个数值,这样就没办法直接过滤任何文件了。
通过对Iceberg表进行数据组织排序,可以使得文件根据字段Id有很好的聚集性。如上图右边部分,通过排序之后,再用 Id =100进行查询,只需要读第一个文件就行,另外 3 个文件通过元数据的 Min/Max值就可以直接过滤掉,这种情况下不需要去扫描所有的文件了,可以大大提高查询性能。
上面举例的是一个线性排序的场景:基于一个或多个字段进行分区内线性全排序,典型应用场景包括:根据 up_id/avid 进行点查/范围查询。线性排序遵循最左匹配的原则,如果第一个字段是一个高基数字段,根据它排序之后,大概率第二个字段是无序的,根据第二个字段去做过滤,通常无法直接过滤掉任何数据文件。
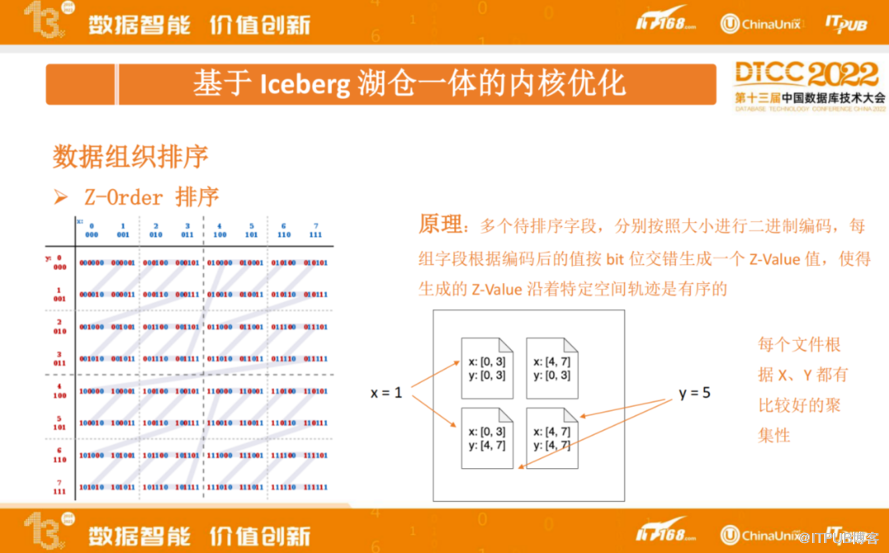
由于线性排序的缺陷,我们内部实现了 Z-order 排序, Z-order 排序基本原理如下:多个待排序字段,分别按照大小进行二进制编码,每组字段根据编码后的值按 bit 位交错生成一个 Z-Value 值,使得生成的 Z-Value 沿着特定空间轨迹是有序的。
如上图的左边部分,Z-Value 沿着 Z字形曲线,对应取值分别是 0、1、2、3… ,是依次递增的。即沿着Z字形是有序的,这也是 Z-order排序名字的由来。
通过 Z-order 排序之后,把左边的图从 x 跟 y 分别从中间做切分,把数据切分成 4 个文件,得到右边图的效果。第一个文件 x 取值范围是 0- 3, y取值范围0- 3,其他几个文件类似。这种情况下,假如是用 x = 1 过滤,只需要去扫描左上角第一个文件和左下角的文件即可。如果用 y = 5 去过滤,只需要去扫描左下角跟右下角的数据文件就可以。这个场景,不管是用 x 还是 y 进行过滤,都有 50% 的过滤效果。当数据越多,生成的数据文件越多,经过 Z-order 排序后,单个字段过滤可以达到80%-90%的过滤效果。
在实际应用场景中,Z-order排序通常会基于 2~4 个字段进行分区内 Z-Order 空间排序。实际测下来,如果Z-order排序的字段过多,比如超过 4 个字段,过滤效果大打折扣。Z-order排序典型应用场景有根据 up_id、avid、time 等多个字段进行点查/范围查询。
二级索引支持
二级索引支持:Bloomfilter 索引,很小的存储开销,支持任意普通类型字段的点查。典型应用场景包括存在较多不同字段过滤场景,适用于相对较高基数的字段;Bitmap 索引:支持多个字段的组合查询,并且支持范围查询。典型应用场景包括单个字段或多个字段组合的点查或范围查询,字段基数不宜过高;BloomRF 索引:较小的存储开销,支持字段的点查和范围查询。典型应用场景包括高基数字段的点查和范围查询;Tokenbf、ngrambf 索引:针对 String 类型数据进行检索,典型应用场景为日志场景中的关键字检索。
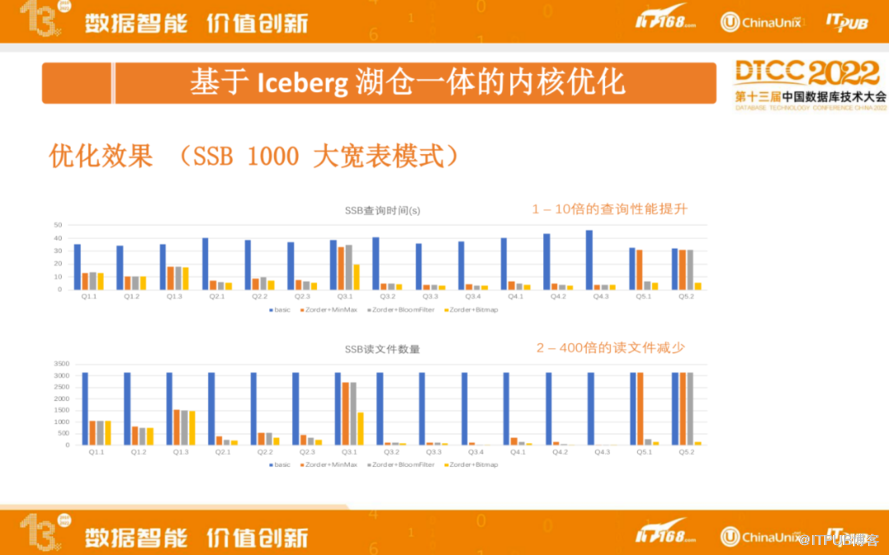
经过数据组织排序,多种二级索引支持,在SSB 1000大宽表模式进行性能测试,整体来看,查询时间有 1- 10 倍查询性能提升。读文件数量性能提升更为明显,有2-400倍的读文件减少。
预计算、星型模型支持
星型模型优化是指在 join 场景下,根据维表过滤字段。通过关联维表,按照维表字段进行数据重新组织,查询时将维表谓词直接进行下推。
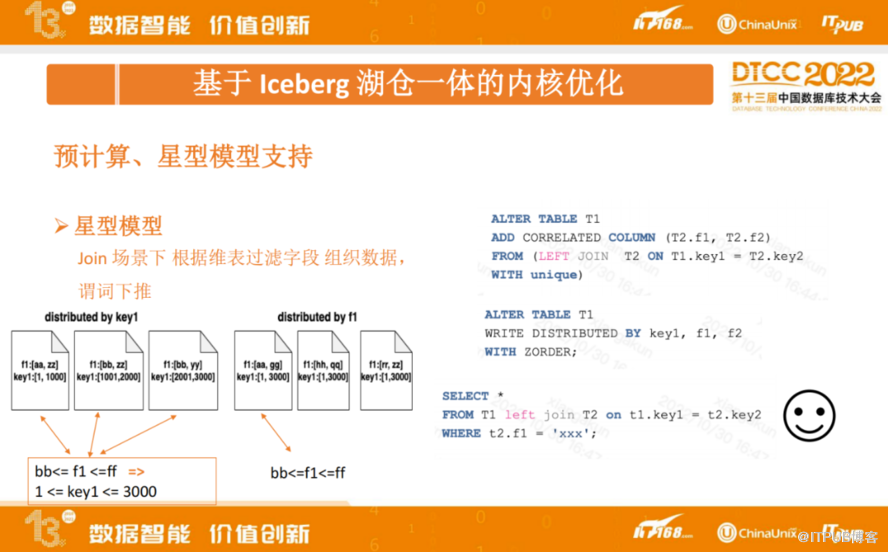
如上图右下角,事实表T1 left join 维表T2,根据某个 key 做关联,然后利用维表的某一个字段去做过滤。熟悉 Spark或 Trino 的同学应该都知道,这种情况下可以利用dynamic filter来提高过滤效率,表T2,通过f1 过滤出key2, key2 可能是一个值,也可能是有限的几个值。key2 即是T1表对应的 Key1 的取值,然后将 key1的取值下推到T1事实表中,理想情况下不需要做全表扫描。实际,我们在做SSB测试的时候也发现了一个问题,在这种情况下,可能查询出来key1是一个很大的范围,比如是 1 到3000。即便数据文件做了排序,由于范围太大,无法达到预想效果。
如何解决以上问题?上图右上角我们拓展了一种 SQL 语法,在事实表上通过关联维表加了一个维表字段。关联关系通过 left join 去关联维表,这里有限制条件unique,也可以支持primary key。 中间 SQL 语句:可以通过新增维表字段 F1作排序,对应的Iceberg元数据,索引每个文件的Min/Max 值。查询时,可以将F1 字段直接下推到事实表,如左图2,这种情况下只需要读一个文件就可以。
预计算主要解决聚合、多表关联场景下大量数据摄入、计算密集导致查询耗时的问题。目前我们实现了单表、多表的预计算,支持多种聚合函数:count、avg、max、min、sum、count_distinct、approx_count_distinct、percentile、top_n,支持查询部分 cube 文件、部分数据文件的场景,计算引擎在 Plan 阶段 通过 iceberg 元数据,判断查询是否能命中预计算,并进行相应的查询改写。
通过SSB 1000 1TB数据查询测试,整体性能有几倍到几十倍的性能提升。
第二部分,总结来看,内核优化核心是,只读取查询所需的数据,尽量减少无用数据的摄入。
智能化管理平台 Magnus
Magnus 背景:
Iceberg 是一个表格式,只提供了数据、元数据读、写 API 的实现,缺乏统一的数据、元数据操作、管理的服务。另外我们引入Iceberg 是为了替换Hive,用户习惯了使用 Hive 表,怎么减少用户使用 Iceberg 表的成本?使得使用起来跟普通的 Hive 表一样?
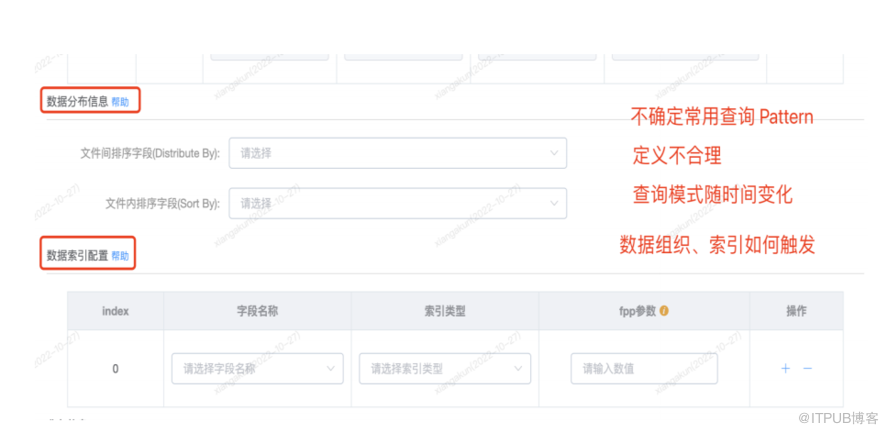
上图是我们数据平台用户建表的一个截图,截图部分是建 Iceberg 表比建普通的Hive表要多出来的一部分。需要用户去填数据分布信息,以及数据索引的配置信息。这对用户而言会产生一些问题。首先,可能用户都不确定常用查询Pattern是什么样的,其次,用户对如何定义数据分布,如何定义索引会有一定的学习和理解成本。还有一种情况,由于查询模式会随时间变化,需要用户频繁去改动,或者用户可能根本未感知到变化,这会导致随时间查询性能逐步下降。另外,上文我们提到的数据组织排序、索引,都只介绍了其定义,并未涉及这些操作是该由谁来触发,交由谁来管理,显然直接交给用户是不合理的。
为了解决上面提到的一些问题,我们开发了智能化管理平台 Magnus。其架构如下:
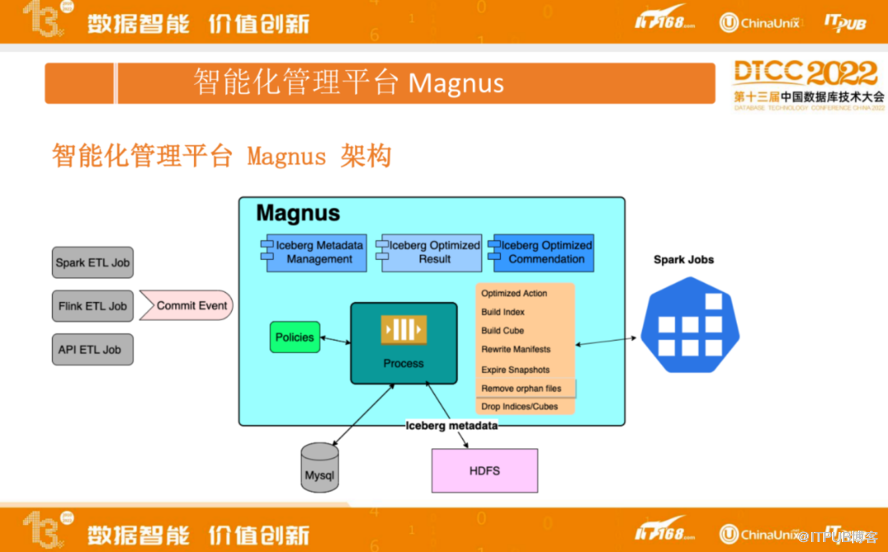
Magnus包括元数据管理、优化结果以及优化推荐三部分。同时Magnus 会去监听Spark 、Flink、 API ETL 等作业的 Commit Event,Commit Event的信息会包含具体是哪一个表、哪个快照操作,操作类型,这些信息都会通知到Magnus。Magnus通过查询HDFS的元数据了解表上有没有定义对应的组织排序、索引等信息,生成后续的操作,对应操作会先落库到数据库里面,待达到相应条件,触发具体的作业执行。
目前支持的作业类型包括Optimized Action(包括对数据进行小文件合并、组织排序等)、构建索引、生成cube、重写元数据(如果元数据都很小,源数据的读取开销不能忽略,这种情况下可以进行元数据重写、合并),此外,还支持快照过期、孤儿文件删除,索引和 cube 删除等,相应的 作业 会使用 Spark 进行执行。
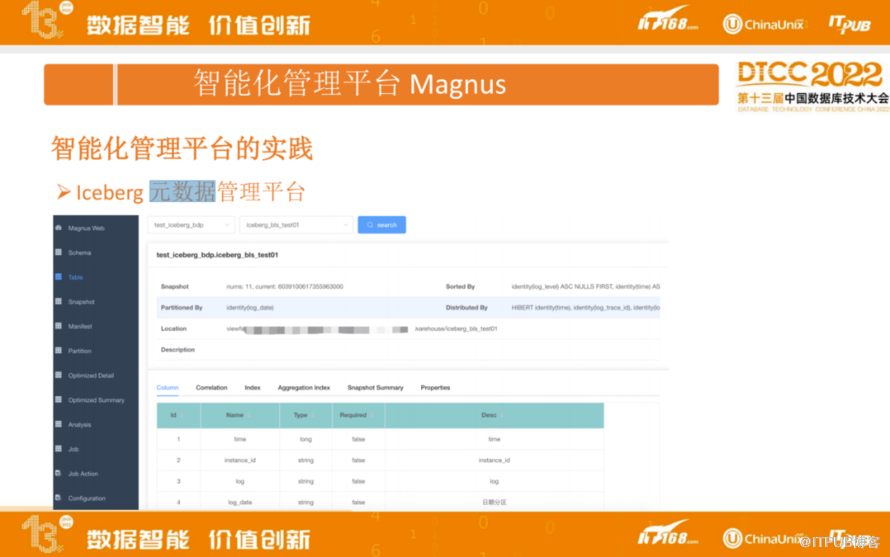
上图为Magnus Iceberg元数据管理平台的界面,包括某个表的快照、manifest、分区统计信息等,以及表的列信息,包括关联列、索引、cube 信息等。此外,还有优化汇总的信息以及分析模块推荐等。
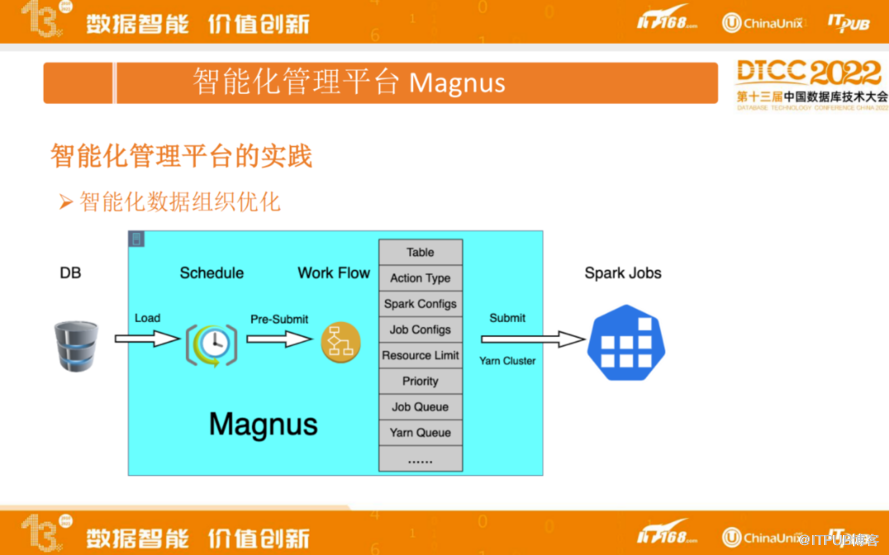
上图为Magnus智能化数据组织优化的流程,待执行任务,会先落地到DB,Magnus的调度任务会把它捞出来准备做提交,提交之前会有一些操作。首先看具体是哪个表,要做什么样的操作,是做组织排序还是建索引或其他操作,根据具体操作统计影响分区文件的大小,进行Spark 资源的分配。关于Resource Limit ,由于我们 Iceberg 表数据存在独立的Hadoop集群,如果白天有很多ETL任务对整个查询性能会有很大影响,所以通过Resource Limit 去限制白天跑的整体任务量,尽量不要去影响Ad Hoc查询。
如果资源达到或超过了设置的最大值,会把 Job 加入等待队列。针对数据可能存在不同的机房,通过分区数据进行探测,获取数据所在机房,并提交到指定的 Yarn Queue,实现多机房之间的调度,最终所有 spark job 通过 Yarn-Cluster模式进行调度运行。
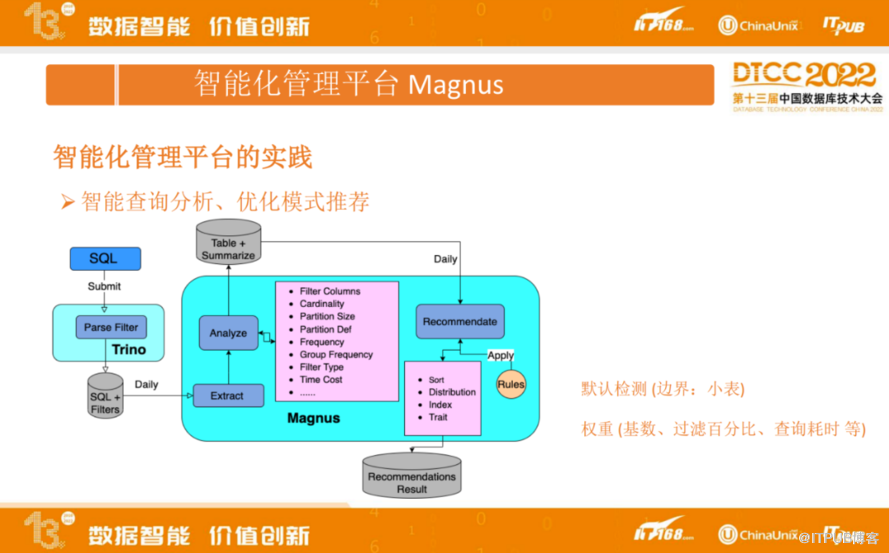
上图为Magnus的智能查询分析与优化模式推荐,右边是Magnus,左边是计算引擎Trino,用户的 SQL 提交到 Trino引擎后,Trino会将能下推到存储的过滤条件解析出来。我们会将每个SQL的Query信息以及能够下推的过滤条件,都保存到 MySQL。
Magnus每天会去抽取历史的查询信息进行分析,分析包括:过滤的条件、条件字段所在表对应的最细粒度分区的基数,分区数据文件大小以及分区定义,也会去看对应的查询过滤字段出现的频率。如果是组合查询,会对组合频率进行统计,并区分是点查还是范围查询,以及查询耗时等统计信息,最终我们会把这些统计信息汇总重新落地到 MySQL。上图Magnus 右侧是一个推荐模块,推荐模块会分析汇总的信息,其中涉及一些规则:首先是默认边界的检测:比如检测是不是小表,如果表的单分区记录数只有百万级别或更少,大概率它只会生成一个文件,如果再去进行Z-order排序是没有意义的。核心点,会对不同的影响因子设置权重、提供一套统一的经验公式。影响因子包括:过滤字段的基数、过滤百分比、查询频次、查询耗时等,最终为每个表推荐出更合理的分区设置、组织排序字段、索引信息、其他Trait等信息。

如上图,是作出推荐结果的依据,统计信息包括每个字段的查询频次,是等值过滤还是范围查询,字段的的基数、不同字段组合查询的耗时等,据此可以推断推荐结果是否合理。
第三部分:总结来看,Magnus 的核心价值就是助力查询加速,降低用户使用湖仓的门槛。
未来规划
我们近期在湖沧一体方向上的规划主要有以下几个方面:一、预计算支持Star Tree,主要是解决维度字段基数过高导致性能衰退的问题。二、历史分析推荐支持预计算。三、历史分析推荐实现真正的智能化, Magnus 的定位是智能化的,但是目前离智能化还有一段距离,推荐结果出来之后,还是需要人工进行推荐结果的应用以及效果的验证对比,未来我们希望能做到不需要人工的参与。四、CDC 数据落地支持,后面会推进更多CDC业务场景的落地。

